
티스토리 뷰
데이터베이스의 저장 및 검색 처리 방식에 대해 다룬다.
색인 자료 구조
해시 색인
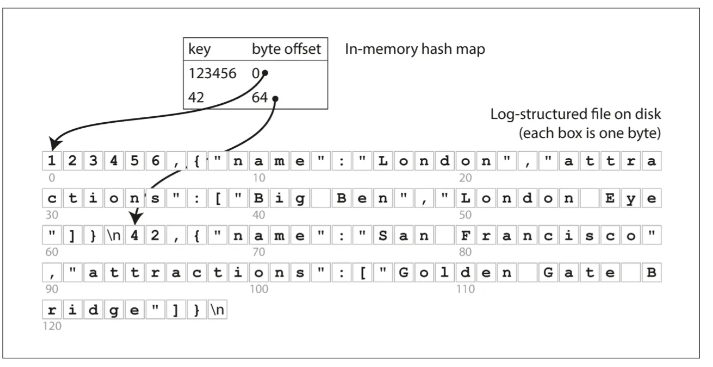
이 방식은 키를 데이터 파일의 바이트 오프셋에 매핑해 인메모리 해시 맵을 유지하는 방식
비트캐스크(bitcask) 에서 사용 — 해시 맵을 전부 메모리에 유지하기 때문에 RAM에 모든 키가 저장,
메모리에 모든 키를 보관할 수 있을 만큼 키 수가 작지만 각 키의 값이 자주 갱신되는 상황(=키당 쓰기 수가 많은 경우) 에 유리
데이터가 저장되는 로그 파일을 무한정 append 하면 디스크 공간이 부족해 질 것 →
컴팩션(compaction) 을 수행하여 각 로그에서 중복된 key 를 버리고 각 키의 최신 값만 유지함
컴팩션 수행 시, 크기를 줄이기 위해 동시에 여러 다른 세그먼트 파일을 병합하게 됨
세그먼트 파일들의 컴팩션과 병합은 백그라운드 스레드에서 이루어지고, 이 과정이 이루어지는 동안 이전 세그먼트 파일을 이용해 읽기 및 쓰기 요청이 이루어지고 이 과정이 끝나면 새로 병합한 세그먼트 파일을 사용하도록 함
각 세그먼트는 각 키를 파일 오프셋에 매핑한 자체 해시 테이블을 가지게 되고, 키의 값을 찾을 때마다 각 세그먼트의 해시 테이블을 확인하게 됨.
병합을 통해 세그먼트 파일의 수를 작게 유지하기 때문에 많은 해시 테이블을 사용할 필요가 없음
실제로 구현할 때 고려해야 할 것들
- 레코드 삭제: 데이터 파일에 특수한 삭제 레코드(tombstone) 을 추가, 로그 세그먼트 병합 시 이 레코드는 무시됨
- 크래시 복구: 크래시 후 재시작 될 경우 인메모리 해시 맵은 손실됨, 전체 세그먼트 파일을 읽어 복구하는 방법은 세그먼트 파일의 크기가 클 수록 오래 걸림, 비트캐스크는 각 세그먼트 해시 맵의 스냅숏을 디스크에 저장해 빠르게 복구할 수 있도록 함
- 동시성 제어: 로그에 데이터를 추가할 때 하나의 쓰기 스레드만 사용, 데이터 파일 세그먼트는 추가 전용이거나 불변이므로 동시에 여러개 읽기 스레드가 읽을 수 있음
추가 전용 로그가 좋은 설계일까?
- 추가와 세그먼트 병합은 순차적인 쓰기 작업 이기 때문에 무작위 쓰기보다 훨씬 빠름
- 이전 값 부분과 새로운 값 부분을 포함한 파일을 나누어 쓰기 때문에 값을 덮어 쓰는 동안 크래시가 나도 고장 복구가 간단함
- 세그먼트 병합은 조각화되는 데이터 파일 문제를 방지할 수 있음
그러나 다음과 같은 제약 사항이 존재함
- 해시 테이블은 메모리에 저장해야 하므로 키가 많으면 문제가 됨 → 디스크에 해시 테이블을 저장하는 방식은 무작위 I/O 접근이 많이 필요함
- 범위 질의에 취약함 → 240101 과 240106 사이를 질의하고자 할 경우 모든 개별 키를 조회해야 함
SS테이블과 LSM 트리
로그 세그먼트 파일의 키-값 쌍을 키로 정렬 된 형태로 유지
이렇게 키로 정렬된 형식을 Sorted String Table(SS 테이블) 이라고 함
해시 색인을 가진 로그 세그먼트와 비교해 어떤 장점이 있을까?
- 세그먼트 병합은 파일이 사용 가능한 메모리보다 크더라도 간단하고 효율적임, 병합 정렬 알고리즘과 유사한데 각 입력 파일을 읽고 각 파일의 첫 번째 키를 봐서 가장 낮은 키를 출력 파일로 복사한 뒤 이 과정을 반복하면 새로운 병합된 세그먼트 파일이 생성됨, 이 파일도 키로 정렬되어 있음. 여러 세그먼트 파일이 동일한 키를 가질 경우, 가장 최근 세그먼트 값만 유지함
- 모든 키의 색인을 유지할 필요가 없다 — SSTable 은 키가 정렬된 형태이므로 B를 찾는다고 했을 때, B가 A와 C 사이에 있다는 것을 알고 있으므로 A 오프셋으로 이동해 B 가 나올때까지 찾으면 된다. 이 부분은 범위 질의도 쉽게 만든다 일부 키에 대한 오프셋에 대한 인메모리 색인이 필요하지만, 희소하다(sparse). 세그먼트 파일 내 수 킬로바이트 당 키 하나로 충분하다 (수 킬로바이트 정도는 빠르게 스캔 가능함)
- 레코드를 압축하여 디스크 공간을 절약하고 I/O 대역폭 사용을 줄인다 — 여러 레코드를 블록으로 그룹화하고 디스크 쓰기 전 압축, 인 메모리 색인은 각 압축된 블록의 시작을 가리킴

red-black tree나 AVL 트리를 이용한다면 임의의 순서로 키를 삽입하고 읽을 때는 정렬된 순서로 읽을 수 있게 된다
이를 바탕으로 데이터 엔진을 다음과 같이 구성할 수 있다
- 쓰기가 들어오면 인 메모리 균형 트리 데이터 구조(e.g. red-black tree) 에 추가함, 이 인 메모리 트리는 멤 테이블(memtable) 이라고 함
- 멤 테이블이 커지면 SS테이블 파일로 디스크에 기록, 이때 멤 테이블은 정렬된 형태이기 때문에 쓰기를 효율적으로 수행할 수 있다. 이 파일은 최신 세그먼트 파일이 되고, 쓰기는 계속 새로운 멤테이블 인스턴스에 기록함
- 읽기 요청 시 먼저 멤테이블에서 키를 찾고 디스크 상의 가장 최신 세그먼트 → 그 다음 최신 세그먼트 .. 이렇게 찾게 됨
- 백그라운드 스레드에서 세그먼트 병합 및 컴팩션 과정을 수행
크래시 복구를 위해, 인메모리에 저장된 멤 테이블에 있는 최신 쓰기를 별도의 디스크 상의 파일에 유지하고 크래시 후 복구를 위해 사용함
이 알고리즘 및 저장소 엔진은 LevelDB, RockDB, Cassandra, HBase 에서 사용함 ..
이 색인 구조는 LSM 트리(Log-Structured Merge-Tree) 저장소 엔진의 기반이 됨
LSM 저장소 엔진은 정렬된 파일 병합과 컴팩션을 기반으로 함
쓰기 작업과 쓰기 중심 워크로드에 효율적

즉 LSM 트리는 인메모리 memtable 에 쓰기 작업을 하면서 디스크 쓰기에 비해 빠르게 쓰기가 가능하고,
memtable은 red-black tree를 이용해 키로 정렬된 순서의 자료구조를 보장함과 동시에 쓰기(append)가 가능하게 됨
또한 백그라운드에서 SS테이블을 지속적으로 병합하여 데이터 크기가 메모리보다 크더라도 더 효과적이다
데이터가 정렬된 순서로 저장되어 있으므로 범위 질의에도 유용함
이 접근법의 디스크 쓰기는 순차적이기 때문에 매우 높은 쓰기 throughput이 보장됨
SS테이블은 append-only 이고, 기존 데이터를 overwrite 하지 않음.
LSM 트리의 최적화 방식은?
- 블룸 필터: 키가 데이터베이스에 존재하지 않는 것을 효율적으로 알려주는 자료구조, 키를 읽기 위한 불필요한 디스크 읽기를 절약할 수 있음
- 압축 및 병합 전략:
- level compaction: scyllaDB 가 사용, 키 범위를 더 작은 SS테이블로 나누고 오래된 데이터는 개별 레벨로 이동해 컴팩션을 점진적으로 진행
- size-tiered: HBase 가 사용, 상대적으로 작고 새로운 SS테이블을 상대적으로 더 오래되고 큰 SS 테이블에 병합함
- 인 메모리 버퍼링 및 배치 쓰기: in-memory structure인 memtable 에 쓰기 연산을 하여 빠르게 쓰기 연산 가능, 이걸 배치로 모아서 디스크에 flush 해주어 disk write 쓰기 횟수를 줄인다, 디스크에 쓸 때 순차로 쓰기 때문에 쓰기 성능을 높임
B 트리
가장 널리 사용되는 색인 구조이다
B 트리는 여러 key와 하위 페이지의 참조(child pointers)를 포함하는 노드를 가진 balanced-tree 임
LSM 트리 색인은 데이터베이스를 가변 크기를 가진 세그먼트로 나누고 순차적으로 세그먼트를 기록
B 트리는 보통 4KB 의 고정 크기 블록이나 페이지로 나누고 한 번에 하나의 페이지 읽기 또는 쓰기를 함
각 페이지는 주소나 위치를 이용해 식별할 수 있고, 하나의 페이지가 다른 페이지를 참조할 수 있음

B 트리에서 한 페이지가 트리의 root 로 지정되고, 색인에서 키를 찾으려면 root 에서 시작함
페이지는 해당 범위 경계가 어디인지 나타내는 여러 키와 하위 페이지의 참조를 담당
최종적으로는 개별 키(리프 페이지(leaf page)) 를 포함하는 페이지에 도달, 이 리프 페이지는 키의 값을 포함하거나 값을 찾을 수 있는 페이지의 참조임
B 트리에서 한 페이지에서 하위 페이지를 참조하는 수를 분기 계수(branching factor) 라고 부름
이 알고리즘은 트리가 계속 균형을 유지(balanced) 하는 것을 보장하기 때문에 n개의 키를 가진 B 트리는 깊이가 항상 O(log n) 이다. 대부분의 트리는 깊이가 3-4 단계정도면 충분하므로 검색하려는 페이지를 찾기 위해 많은 페이지 참조를 따라가지 않아도 됨
B 트리에서 키의 값을 갱신하려면 키를 포함하고 있는 리프 페이지를 검색하고 페이지의 값을 바꾼 다음 디스크에 다시 기록
새로운 키를 추가하려면 새로운 키를 포함하고 있는 범위의 페이지를 찾아 해당 페이지에 키와 값을 추가
만약 페이지에 충분한 여유 공간이 없다면 페이지를 반 쯤 채워진 페이지 두 개로 나누고 상위 페이지가 새로운 키 범위의 하위 부분을 알 수 있게 갱신함
즉 B 트리에서 기본적인 쓰기 동작은 새로운 데이터를 디스크 상의 페이지에 덮어씀
덮어쓰기가 페이지 위치를 변경하지 않고, 페이지를 가리키는 모든 참조는 온전하게 남음
Reliable한 B Tree를 만드는 방법은?
- 쓰기 전 로그(write-ahead log, WAL) : 재실행 로그(redo log) 라고도 함, 트리 페이지에 변경된 내용을 적용하기 전에 모든 B트리의 변경 사항을 기록하는 추가 전용 파일, 크래시 후 복구할 때 B 트리를 다시 복구하는데 사용함. 삽입 동작이 많아져 여러 다양한 페이지를 덮어쓰기 할 때, 페이지에 충분한 여유 공간이 없어 페이지를 분할하고 분할된 두 하위 페이지의 참조를 갱신하게끔 상위 페이지를 덮어써야 하는데 일부 페이지만 기록하고 크래시 날 경우 어떤 페이지와도 부모 관계가 없는 고아 페이지 가 생성될 수 있다, 이런 상황을 복구하기 위해 WAL 에 변경사항을 기록해 둠
- 래치(latch): 다중 스레드가 동시에 B트리에 접근해서 같은 자리의 페이지를 갱신하려고 할 때, 가벼운 잠금인 래치로 동시성을 제어함
B Tree의 최적화 방식은?
- copy on write scheme : 페이지 덮어 쓰기와 고장 복구를 위해 WAL 대신 CoW 사용, 변경된 페이지는 다른 위치에 기록하고 상위 페이지에 새로운 버전을 만들어 새로운 위치를 가리키게 함
- 키를 축약: 트리 내부 페이지에서 키가 키 범위 사이의 경계 역할을 하는데 충분한 정보만 제공, 페이지 하나에 키를 많이 채우면 트리는 높은 분기 계수를 가지며 이는 트리의 깊이 수준을 낮출 수 있음
- 리프 페이지를 디스크 상의 연속된 순서로 나타내게 트리 배치: 키 범위가 가까운 페이지들이 디스크 상에 가까이 있지 않다면 정렬된 순서로 키 범위의 많은 부분을 스캔해야 한다면 모든 페이지에 대해 디스크 찾기를 해야하기 때문에 비효율 적일 수 있음. 디스크 상에 리프 페이지를 연속되게 배치하여 효율적으로 디스크 찾기를 한다. LSM 트리의 경우, 병합하는 과정에서 저장소의 큰 세그먼트를 한 번에 다시 쓰기 때문에 정렬된 연속된 키를 디스크에서 서로 가깝게 유지하기가 더 쉽다. B 트리의 경우 트리가 커지면 디스크에서 연속된 상태로 순서를 유지하기가 어려움
- 트리에 포인터를 추가 : 각 리프 페이지갸 헝제 페이지에 대한 참조를 가지면 상위 페이지로 이동하지 않아도 순서대로 키를 스캔할 수 있음
LSM 트리 vs B 트리
쓰기는 LSM 트리가 더 빠름
읽기는 보통 B tree 가 빠름 (LSM 트리에서는 읽기 연산 시 컴팩션 단계에 있는 여러가지 데이터 구조와 SS 테이블 확인해야 하기 때문)
LSM 트리는 보통 B 트리보다 쓰기 처리량을 높게 유지할 수 있는 이유?
- **쓰기 증폭(write amplification)**이 낮음: 쓰기 증폭은 데이터베이스 쓰기 한 번이 DB 수명 동안 디스크에 여러번의 쓰기를 야기하는 효과임. LSM 트리는 B 트리처럼 여러 페이지를 덮어쓰는 것이 아니라 순차적으로 컴팩션 된 SS테이블을 쓴다. B 트리는 모든 데이터 조각을 최소한 두 번 기록해야 함(WAL 한 번, 트리 페이지에 한 번)
- 압축률이 더 좋음: B트리 저장소 엔진은 파편화로 인해 사용하지 않는 디스크 공간 일부가 남게 됨(페이지를 나누거나 로우가 기존 페이지에 맞지 않을 때 페이지의 일부 공간은 사용하지 않게 됨). 반면 LSM 트리는 page 단위가 아니라 파편화를 없애기 위해 SS 테이블을 다시 기록하기 때문에 저장소 오버헤드가 낮음
LSM 트리의 drawback?
- 비싼 컴팩션 연산: 컴팩션 연산이 끝날 때까지 진행 중인 읽기와 쓰기의 요청이 대기해야 하는 상황이 발생할 수 있음
- 유한한 쓰기 대역폭: 초기 쓰기, 멤테이블을 디스크로 쓰기, 백그라운드에서 수행되는 컴팩션 스레드가 대역폭을 공유해야 함. DB 가 커질수록 컴팩션을 위해 더 큰 디스크 대역폭이 필요하게 됨
- 컴팩션이 유입 쓰기 속도를 따라갈 수 없을 수 있음: 디스크 상에 병합되지 않은 세그먼트 파일이 늘어나게 되고, 읽을 때 이 세그먼트 파일을 모두 확인해야 되기 때문에 읽기가 느려질 수 있음
- 같은 키의 다중 복사본이 다른 세그먼트에 존재함: B트리의 경우 각 키가 색인의 한 곳에만 정확히 존재, LSM 트리의 경우 같은 키의 다중 복사본이 다른 세그먼트에 존재할 수 있음
기타 색인 구조
- 기본키 색인: 키-값 색인. 관계형 테이블에서 하나의 row를, 문서 데이터베이스의 하나의 문서를 고유하게 식별할 수 있게 함
- 보조 색인(secondary index): create index ~~ 해서 생성하는 인덱스, 키가 고유하지 않다는 점임. 같은 키를 가진 많은 로우가 있을 수 있음
색인에서 키의 값(value)는 1. 실제 로우 2. 다른 곳에 저장된 로우를 가리키는 참조가 될 수 있다
2.의 경우 로우가 저장된 곳을 힙 파일(heap file) 이라고 하고 특정 순서 없이 데이터를 저장함
힙 파일은 키를 변경하지 않고 값을 갱신할 때 효율적임, 새로운 값이 이전 값보다 많은 공간을 필요로 하지 않으면 레코드를 제자리에 덮어 쓸 수 있음
새로운 공간이 많은 공간을 필요로 한다면, 힙에서 충분한 공간이 있는 새로운 위치로 이동하고 모든 색인이 레코드의 새로운 힙 위치를 가리키도록 갱신하거나 이전 힙 위치에 전방향 포인터를 남겨줘야 함
색인에서 힙 파일로 이동하는 건 읽기 성능에 불이익이 많아서 클러스터드 색인(clustered index) 를 사용
클러스터드 색인이란 색인 안에 바로 색인된 로우를 저장하는 방식임 (MySQL 의 InnoDB 엔진에서는 기본키가 클러스터드 색인이고 보조 색인은 기본키를 참조), 키 값(색인)을 기준으로 테이블이나 뷰의 데이터 행을 정렬하고 디스크 상에 저장. 데이터 페이지의 행 순서가 인덱스 행 순서와 일치하는 인덱스. 클러스터드 색인의 리프 노드는 실제 row 임(actual data) .
읽을 때 테이블을 거치지 않고 색인으로만 읽을 수 있으므로 읽기 성능 빨라지고, sequential 하게 읽을 수 있으므로 범위 질의에 유용(비슷한 row들은 같은 data page 에 있을 확률이 높으므로). 쓸 때 다시 데이터를 rearrange 해야하므로 쓰기 성능은 느려질 수 있음
비클러스터드 색인이란 색인 안에 데이터의 참조만 저장하는 방식임
클러스터드 색인이 있을 경우, 비클러스터드 색인의 리프 노드에는 클러스터드 인덱스 키가 들어가고 그렇지 않을 경우 힙 파일의 row locator 가 들어감
비클러스터드 색인에서 클러스터드 인덱스 키가 들어가는 경우, 보통 다음과 같은 과정이 일어남 비클러스터드 색인에서 쿼리에 매칭되는 각 행을 식별하고 → 테이블의 데이터 페이지에서 이 해당 행에 대한 열 정보를 검색해야 하기 때문에 클러스터드 인덱스를 이용해서 탐색하게 됨(Key Lookup)
다만 조회하려는 row가 많아질 경우, query optimizer 가 비클러스터드 인덱스를 사용해서 결과 rows 들을 모두 key-lookup 하는 비용보다 전체 테이블 스캔을 하는 비용이 더 싸다고 판단할 경우 비클러스터드 색인이 사용되지 않을 수 있다 ..
따라서 색인 안에 조회하려는 모든 column 이 존재한다면, 인덱스만 사용하고도 쿼리할 수 있다 (=key-lookup을 사용하지 않고도 결과 집합을 구할 수 있다) → 이 개념이 커버링 인덱스.
커버링 색인(covering index), 포괄열이 있는 색인(index with included columns) 은 색인 안에 테이블의 칼럼 일부를 저장, 이렇게 하면 색인만 사용해 일부 질의에 응답이 가능함, 실제 테이블에 접근할 필요가 없음 (이때 색인이 질의를 커버했다고 함)
읽기 성능을 높일 수 있지만 추가적인 저장소가 필요하고 쓰기 과정에 오버헤드가 발생할 수 있음
결합 색인(concatenated index) 은 다중 컬럼 색인으로, 결합 색인은 하나의 컬럼에 다른 컬럼을 추가하는 방식으로 하나의 키에 여러 필드를 결합함 (e.g. (성, 이름) 을 키로 하는 색인)
(위도, 경도) 검색과 같은 한 번에 여러 칼럼에 질의하는 것이 일반적일 때 다차원 색인을 사용
퍼지 색인(fuzzy index) 은 유사한 키에 대해 질의하는 것. 전문 검색 엔진에 활용
Lucene 에서 인메모리 색인은 트라이와 유사
인메모리 데이터베이스는 모든 것을 메모리에 보관
크래시 날 경우를 대비 해 디스크에 변경 사항의 로그를 기록하거나 디스크에 주기적인 스냅숏을 기록하거나 다른 장비에 인메모리 상태를 복제함. 지속성을 위해 디스크에 추가 전용 로그를 쓰고, 읽기는 전적으로 인메모리에서 수행
트랜잭션 처리 및 분석 시스템
OLTP (트랜잭션 처리 시스템): 트랜잭션 처리를 위한 시스템, 적은 수의 레코드, 사용자 입력을 낮은 지연 시간으로 기록, 주로 기가바이트에서 테라바이트
OLAP(분석 시스템): 많은 레코드에 대한 집계, 대규모 불러오기, 테라바이트에서 페타바이트
데이터 웨어하우스 는 OLTP 작업에 영향 주지 않고 질의할 수 있는 DB, 다양한 OLTP 시스템에 있는 데이터의 읽기 전용 복사본, 각 OLTP 시스템에 ETL 해서 데이터를 import 하게 됨, 분석 접근 패턴에 맞게 최적화하여 OLTP의 데이터를 변형하여 저장함

- 사실 테이블: 각 로우는 특정 시각에 발생한 이벤트
- 차원 테이블: 사실 테이블의 column이 참조하는 테이블로, 각 row는 이벤트의 속성을 가리킴
이 스키마를 조금 더 세분화한 snowflake schema 도 있음, 각 차원 테이블을 하위 차원으로 더 세분화한 case
컬럼 지향 저장소
일반적으로 데이터 웨어하우스 질의는 한번에 4 ~ 5 개의 컬럼만 접근하는데, 대부분의 OLTP 데이터베이스 저장소는 로우 지향 방식으로 데이터를 배치하게 된다. 이 경우 사실 테이블에서 대용량 데이터 result set을 조회하고자 한다면, 모든 컬럼을 가진 모든 로우를 메모리로 적재한 다음 구문을 해석해 필요한 조건을 충족하지 않은 로우를 필터링 해야 한다.. 이 작업은 시간이 오래 걸리는 작업임
따라서 모든 값을 한 row에 저장하지 않고 각 컬럼 별로 모든 값을 함께 저장하는 컬럼 지향 저장소 를 사용하면 작업량을 줄일 수 있다
일부 컬럼만 질의하나, 수 억개의 row가 페치되야 하는 OLAP 에 적합
각 컬럼을 개별 파일에 저장하고 질의에 사용하는 컬럼만 읽고 구문분석하면 된다
칼럼 지향 저장소 배치는 각 컬럼 파일에 포함된 로우가 모두 같은 순서인 점에 의존함
컬럼 압축
질의에 필요한 컬럼만 디스크에서 읽어 적재하는 것 외에,
데이터를 압축하면 디스크 처리량을 줄일 수 있음
컬럼 지향 저장소는 압축에 적합함

비트맵 부호화 를 이용해 칼럼을 압축할 수 있음
n개의 고유값을 가진 칼럼을 가져와 n개의 개별 비트맵으로 변환할 수 있음
고유 값 하나가 하나의 비트맵이고, 각 로우는 한 비트를 가진다. 각 로우가 해당 값을 가지면 비트가 1, 아니면 0임
n이 매우 작을 경우, 로우 당 하나의 bit 로 저장할 수 있지만 (대략 n이 255 이하일 경우), n이 더 클 경우 대부분의 비트맵은 0이 더 많을 경우 이 경우 위 그림과 같이 런 렝스 부호화 를 이용해 압축할 수 있음
비트맵을 이용해 질의를 더 효과적으로 수행할 수 있음
where product_sk in (30, 68, 89): 3개 종류에 대한 비트맵 세 개를 적재하고 세 비트맵의 비트 OR 을 계산
where product_sk = 31 and store_sk = 3: product_sk = 31, store_sk = 3 로 비트맵을 적재하고 비트 AND를 계산 (이 연산은 각 컬럼에 동일한 순서로 로우가 포함되기 때문에 가능)
컬럼 저장소 배치는 CPU 주기를 효율적으로 사용하기 적합함
질의 엔진은 압축된 컬럼 데이터를 CPU 의 L1 캐시에 맞게 딱 덩어리로 나누어 가져오고 이 작업을 타이트 루프에서 반복함. 칼럼 압축을 사용하게 되면 L1 캐시에 더 많은 로우를 저장할 수 있고,
벡터화 처리 를 이용해서 비트 AND, OR 연산자는 압축된 데이터 컬럼 덩어리를 바로 연산할 수 있게 해줌
컬럼 저장소를 순서 정렬 하여 질의 최적화기가 해당 범위에만 해당하는 로우만 스캔하도록 할 수 있음
또한 순서 정렬은 컬럼 압축에 도움이 된다 — 기본 정렬 컬럼에 고유 값을 많이 포함하지 않는다면, 기본 정렬 컬럼은 연속해서 같은 값이 길게 반복되고 런 렝스 부호화 를 통해 수식업 개의 로우를 가진 테이블이라도 수 킬로바이트로 컬럼을 압축할 수 있음
또한 데이터를 복제하여 다양한 방식으로 정렬해서 저장해서 질의를 처리할 때 질의에 가장 적합한 버전을 선택할 수 있게 할 수 있음
칼럼 지향 저장소에 쓰기
칼럼 지향 저장소, 압축, 정렬은 읽기 질의를 빠르게 하지만 쓰기를 어렵게 만들 수 있음
LSM 트리를 이용해서 모든 쓰기는 정렬된 구조에 추가되고, 인 메모리에서 충분한 쓰기를 모으면 디스크의 칼럼 파일에 병합하고 대량으로 새로운 파일에 기록하는 방식을 쓸 수 있음
정리
OLTP는 트랜잭션 처리 최적화 시스템으로, 보통 사용자 대면이다. 질의 마다 적은 수의 레코드만 다루고
애플리케이션은 키의 일부만 사용하는 레코드를 요청하고, 저장소 엔진은 요청한 키의 데이터를 찾기 위해 색인을 사용하는데 이 경우는 디스크 탐색이 병목이다
- SS 테이블과 LSM 트리: 파일의 추가나 삭제만 가능하고 한번 쓰여진 파일은 갱신하지 않음. 파일들을 계속해서 병합 및 압축함. 카산드라, HBase, 루씬 등이 포함
- B-tree: 갱신 관점에서 덮어쓰기 할 수 있는 고정 크기 페이지 셋으로 디스크를 다룸.
OLAP는 분산 최적화 시스템으로, 주로 질의에 사용되는 컬럼은 적으나 결과 set이 많은 수의 로우를 포함하는 것이 특징. 많은 수의 로우를 스캔해야 한다면 색인을 사용하는 방법은 적절치 않고(색인을 사용해서 로우를 빠르게 찾는다고 하더라도 결국 모든 로우를 메모리에 적재해야 한다), 질의가 디스크에서 읽는 양을 최소화하기 위해 데이터를 매우 작게 부호화해야 함. 이 경우 컬럼 지향 저장소가 각 컬럼별로 값을 저장하고, 압축하기 때문에 OLAP 에 적합할 수 있음.
참고:
https://www.scylladb.com/glossary/log-structured-merge-tree/
https://mangkyu.tistory.com/286
https://www.tinybird.co/blog-posts/what-is-a-columnar-database
'공부 > Database' 카테고리의 다른 글
| 트랜잭션과 격리성 레벨 (1) | 2025.04.06 |
|---|---|
| [Desinging Data-Intensive Applications] 02장. 데이터 모델과 질의 언어 (0) | 2025.02.16 |