
티스토리 뷰
분산 키-값 저장소
분산 시스템 설계 시 고려해야 할 점들
CAP 정리
- 데이터 일관성 (Consistency) : 분산 시스템에 접속하는 모든 클라이언트는 어떤 노드에 접속했느냐에 상관없이 언제나 같은 데이터를 봐야 함
- 가용성 (Availability) : 분산 시스템에 접속하는 클라이언트는 일부 노드에 장애가 발생하더라도 항상 응답을 받을 수 있어야 함
- 파티션 감내 (Partition tolerance): 파티션은 두 노드 사이에 장애가 발생하였음을 의미, 파티션 감내는 네트워크에 파티션이 생기더라도 시스템은 계속 동작함을 의미
이 3가지 요소를 동시에 만족시키는 분산 시스템을 설계하는 것은 불가능하다. 네트워크 장애는 피할 수 없는 것으로 여겨지므로, 파티션 감내는 반드시 감내할 수 있도록 설계되어야 함. 보통 CP 시스템 (일관성 + 파티션 감내), AP 시스템 (가용성 + 파티션 감내) 중에 선택하게 된다.
만약 n1, n2, n3 노드가 있고 n3 이 네트워크 장애로 통신이 단절된다면
- CP 시스템: 일관성을 선택하였으므로, 데이터 불일치 문제를 피하기 위해 n1, n2에 쓰기 연산을 중단시켜야 함 (가용성 깨짐), 네트워크 장애가 해결될 때까지 응답 오류를 반환해야 함
- AP 시스템: 가용성을 선택하였으므로, n1,n2 에 쓰기 연산을 허용, 낡은 데이터를 반한할 위험이 있더라도 읽기 연산 허용(일관성 깨짐)
데이터 파티션
(5장 참고) 데이터를 파티셔닝해서 저장하기 위해 고려해야 할 점
- 데이터를 여러 서버에 고르게 분산
- 노드가 추가되거나 삭제될 때 데이터의 이동을 최소화
DynamoDB에서는 안정 해싱(consistent hashing) 을 사용.
기본 컨셉은 아래와 같다
- 해시 공간이 ring 과 같은 공간에 할당, 각 노드는 hash function을 거쳐 ring의 특정 position을 할당. key 도 마찬가지로 hash function을 거쳐 ring의 시계방향에 가장 가까운 쪽의 Node 로 할당됨
그러나 다음과 같은 문제가 발생할 수 있음.
- 노드가 링의 공간(해시 공간)에 랜덤하게 배치될 수 있으며, 이는 불균형을 초래할 수 있음
- 노드 성능을 반영하지 못한다(oblivious to the heterogeneity in the performance of nodes.) 저성능 노드와 고성능 노드가 같은 양의 데이터를 핸들링한다면, 저성능 노드가 병목이 발생할 수 있다
이 문제를 해결하기 위해 가상 노드(virtual node) 개념이 존재한다.
각 노드는 한 개 이상의 가상 노드를 가지게 됨.
- 물리적인 노드(서버)에 여러 개의 가상 노드를 매핑하여, 노드의 성능에 따라 더 많은 가상 노드를 배정: 예를 들어, 성능이 좋은 노드는 해시 링에서 더 많은 가상 노드를 가지게 되므로 더 많은 데이터를 저장하고 처리
- 노드 간 부하가 균등하게 분배될 수 있음
- 규모 확장 및 자동화가 가능하다 - 시스템 부하에 따라 서버가 자동으로 추가되거나 삭제되게 할 수 있음
데이터 다중화

데이터를 N개 서버에 비동기적으로 다중화
Dynamo의 경우, 특정 key가 1개의 코디네이터에 배정되서 코디네이터가 데이터 복제를 책임지는 형태
위 그림에서 Key K의 경우, 코디네이터의 시계방향에 있는 N-1 개의 노드에 복사되게 됨
각 키는 preference list 를 가지는데, 이 키를 저장할 노드의 목록을 의미한다. 단 이 목록에 virtual node 가 포함되어 실제 N개보다 적은 물리 서버에 저장될 수 있다 → 이 목록에 오직 Physical node 만 포함하도록 설계할 수 있음
데이터 일관성
여러 노드에 분산된 데이터는 적절히 동기화가 되어야 함
정족수 합의(Quorom Consensus) 프로토콜을 사용하면 읽기 / 쓰기 모두에 일관성을 부여할 수 있다
- N = 사본 갯수
- W = 쓰기 연산에 대한 정족수, 쓰기 연산이 성공한 것으로 간주되려면 W개의 서버로부터 쓰기 연산이 성공했다는 응답을 받아야 함
- R = 읽기 연산에 대한 정족 수, 읽기 연산이 성공한 것으로 간주되려면 R개의 서버로부터 응답을 받아야 함
주의할 점은 W개의 서버에 데이터가 동기화된다는 것이 아니라, 코디네이터(중재자)가 최소 W개의 서버로부터 성공 응답을 받는다는 뜻이다.
W, R 값이 커질 수록 시스템의 일관성의 수준은 향상되지만, 중재자는 항상 제일 느린 서버로부터 응답을 받아야 하므로 latency는 감소할 것이다.
보통 W+ R > N의 경우 강한 일관성이 보장됨. 일관성을 보증할 데이터가 최소 1개는 겹치기 때문이다.
W + R ≤ N 은 강한 일관성이 보장되지 않으나, latency는 증가한다.
일관성 모델
일관성 모델은 데이터 일관성 모델의 수준을 결정한다.
- 강한 일관성: 모든 읽기 연산은 가장 최근에 갱신된 결과를 반환한다
- 약한 일관성: 읽기 연산은 가장 최근에 갱신된 결과를 반영하지 못할 수 있다
- 최종 일관성(eventual consistency): 약한 일관성의 형태로, 갱신 결과가 결국에는 모든 노드에 동기화 되는 모델임
최종 일관성의 경우, 쓰기 연산이 병렬적으로 발생하면 시스템에 저장된 값의 일관성이 깨질 수 있음.
일관성 불일치 해소
Dynamo의 경우, 데이터 비저닝 을 통해 이 문제를 해소함.
- 버저닝은 데이터를 변경할 때마다 새로운 버전을 만들고, 각 버전은 변경 불가능(Immutable) 함.
- 동시성 문제 발생 시, 특정 객체(데이터)에 각각 다른 버전이 생길 수 있으며, 충돌이 발생했으니 이건 나중에 reconcile 해야 함.
충돌 감지 및 reconcile 을 위해 벡터 시계(vector clocks) 를 사용
- (node, counter) 의 쌍으로 이루어짐
- 각 쌍은 모든 object의 version 마다 존재
- 각 쌍이 서로 충돌되는 데이터인지 (parallel branch), 선후 관계를 가지는 데이터인지 결정할 수 있다
- 첫 번째 쌍의 counter 가 두 번째 쌍의 모든 노드의 counter 보다 작으면 첫 번째 쌍은 두 번째 쌍의 이전 버전이다
- 그렇지 않으면 두 쌍은 충돌되었고, reconcile 이 필요하다

데이터 D를 서버 Si에 기록하고자 한다면
- [Si, vi] 가 있으면 vi 를 증가
- 그렇지 않으면 새 항목[Si, 1] 를 만듦
읽을 때 충돌이 발생할 경우 충돌된 모든 version을 반환한다 → 클라이언트가 직접 해결하도록 함
충돌된 버전이 있을 경우 클라이언트는 이 버전들을 보고 reconcile 을 수행하고 충돌된 버전들을 단일 버전으로 병합하게 됨
벡터 시계 방식의 경우 2가지 단점이 있다
- 클라이언트에서 충돌 해소 로직 구현 - 충돌 로직 해소 방식에는 보통 2가지가 있음
- LWW (Last write wins): 타임 스탬프를 비교해서 가장 최신으로 병합
- application-level logic merged: 애플리케이션 로직 따라 병합
- 벡터 시계의 벡터 사이즈가 빨리 늘어날 수 있다 - vector clock의 size limit 을 설정하여 해결 가능. (threshold 설정)
장애 처리
장애 감지
가십 프로토콜 을 이용해 분산형 장애 감지를 함
각 노드는 멤버십 목록이 있다. 동작 방식은 아래와 같음.
- 각 노드는 멤버십 목록을 유지
- 노노드는 주기적으로 박동 카운터 증가시키고, 무작위로 선정된 노드들에게 자기 박동 카운터 목록을 보냄
- 박동 카운터 목록을 받은 노드는 멤버십 값을 최신 값으로 갱신
- 박동 카운터 값이 일정 시간동안 갱신되지 않으면 해당 멤버는 장애 상태인 것으로 간주
가십 프로토콜을 이용해 다음 과정을 거치게 된다.
- 자신이 알고 있는 정보를 상대 노드에게 전파
- 상대 노드도 받은 정보를 기반으로 다른 노드들에게 전파
- 이 과정을 반복하면서 전체 네트워크에 정보가 전파됨
가십 프로토콜을 이용해 최종적 일관성을 달성할 수 있으며, 랜덤하게 다른 노드들과 정보 교환된 것이 전체 네트워크로 확산된다.
일시적 장애 처리
느슨한 정족수(sloppy quorom) 를 이용해, 해시 링에서 가장 가까운 N개를 쿼럼으로 삼기보다 건강한 N개의 서버를 쿼럼으로 지정한다. (장애 서버는 무시한다)
임시 위탁 기법(hinded handoff): 장애 상태인 서버로 가는 요청을 다른 서버가 처리하고, 그동안 발생한 변경사항은 주기적으로 스캔되는 local database 에 남겨두고, 장애 서버가 복구되었을 때 이 hint를 그 서버에 전달한다.
즉 네트워크 장애가 있어도 읽기 / 쓰기 연산이 가능하도록 한다 (=high availibility)
영구적 장애 처리
머클 트리(Merkle tree) : 사본 간의 일관성이 망가진 상태를 탐지하고 전송 데이터 양을 줄이기 위해 사용된다. 리프 노드일 경우, 데이터 블록의 해시 값이 저장되며 리프 노드가 아닐 경우 각 자식 노드 레이블로부터 계산된 해시 값이 저장된다. (아래 그림 참고)
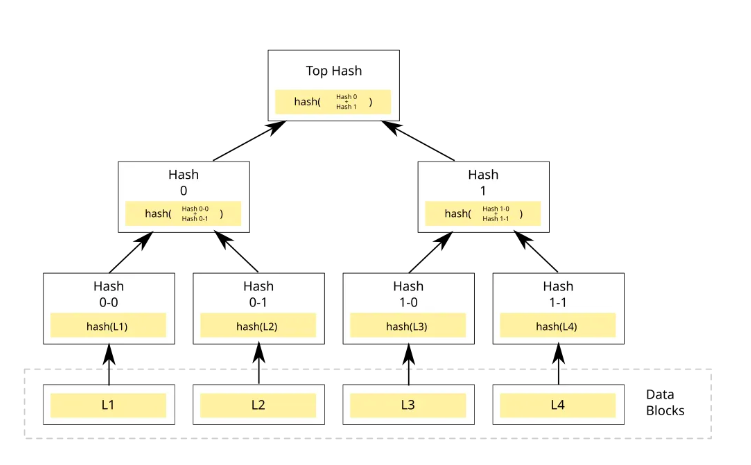
두 머클 트리의 비교는 루트 노드의 해시 값을 비교하는 것으로 시작, 점차 아래쪽으로 탐색해 가면서 해시 값이 다른 노드를 찾아서 다른 데이터를 갖는 버킷을 찾아서 그 버킷들만 동기화함
버킷 트리의 이점?
- 레플리카 간 일관성이 깨졌을 때, 동기화해야 하는 데이터의 양을 줄일 수 있다 (=해시 값이 다른 데이터들만 동기화한다)
읽기, 쓰기 처리
쓰기 처리
분산 키-값 저장소에서 쓰기를 처리하는 방식은 DDIA 03장 - 저장소와 설계에 더 자세하게 나와있다 ..
간단히 정리하면 아래와 같다.
- 인메모리 memtable 에 쓰기를 진행 (이 memtable 은 주로 red-black tree 자료구조이며, red-black tree는 임의의 순서로 write 해도 읽을 때 정렬된 순서로 읽힌다) , 추후 크래시를 대비해 커밋 로그에 쓰기 요청이 기록된다
- memtable (=메모리 캐시) 이 가득차면 데이터는 디스크에 있는 SSTable 에 기록된다
- SSTable 은 키-값 쌍을 정렬된 리스트 형태로 관리하는 테이블
- memtable 은 정렬된 형태이기 때문에 쓰기를 효율적으로 수행할 수 있다. 이 파일은 최신 세그먼트 파일이 되고, 쓰기는 계속 새로운 멤테이블 인스턴스에 기록함
- 백그라운드 스레드에서 SSTable의 병합 및 컴팩션 과정을 처리
읽기 처리
- 읽기 요청 시 먼저 멤테이블에서 키를 찾고 디스크 상의 가장 최신 세그먼트 → 그 다음 최신 세그먼트 .. 이렇게 찾게 됨
- 다만 없는 key를 찾을 경우엔 모든 세그먼트(=모든 SSTable) 을 뒤져야 하므로, 이럴 땐 성능이 떨어질 수 있으므로 블룸 필터 를 사용한다
- 블룸 필터: 블룸 필터(Bloom Filter)는 공간 효율적인 확률적 데이터 구조로, 특정 요소가 집합(Set)에 존재하는지 여부를 빠르게 판별, 해당 키가 없을 가능성이 높은 SSTable을 건너뛰도록 도와줌 (SSTable에 키가 저장되어 있는지 사전에 확인하는 캐시 역할)
- scylladb의 경우 멤테이블에 쿼리한 키가 있는지 블룸 필터로 체크하고, 있으면 반환한다. 키가 없는 경우 Multi-level 로 세그먼트를 찾는다 ..
정리

- 클라언트는 키-값 저장소가 제공하는 API (get, put) 와 통신
- 중계자는 클라이언트에게 키-값 저장소에 대한 proxy 역할을 하는 노드 → 중계자에게 읽기, 쓰기 요청 보내면 적절한 노드에 매핑시켜 줌
- 노드는 안정 해시의 링 위에 분포한다
- 노드는 자동으로 추가, 삭제 될 수 있도록 완전히 분산
- 데이터는 여러 노드에 다중화된다 (replication)
- 모든 노드는 같은 책임을 지므로 single point of failure 는 발생하지 않는다
출처:
가상 면접 사례로 배우는 대규모 시스템 설계 기초 6장
https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
'공부 > System Architecture' 카테고리의 다른 글
| 실험 플랫폼 설계 (Experimentation Platform) (2) | 2025.07.13 |
|---|---|
| [System Design Interview] Chapter.13 검색어 자동 완성 시스템 (0) | 2025.06.08 |
| Domain Driven Design 개요 (1) | 2025.06.07 |
| Design a Notification Service / Usecase of Netflix's Push Server System (0) | 2025.05.25 |
| [System Design Interview] Chapter05. 안정 해시 설계 (0) | 2025.03.01 |