
티스토리 뷰
컨슈머와 컨슈머 그룹
컨슈머는 카프카에서 토픽을 구독하고 구독한 토픽들로부터 메시지를 받는 주체
주로 여러 개의 컨슈머가 같은 토픽으로부터 데이터를 분할해서 읽어옴
카프카 컨슈머는 보통 컨슈머 그룹 의 일부로서 작동하고, 동일한 컨슈머 그룹에서 여러 개의 컨슈머들이 동일한 토픽을 구독할 경우 각각의 컨슈머는 해당 토픽에서 서로 다른 파티션의 메시지를 받게 됨

컨슈머 그룹에서 컨슈머를 추가하면 토픽에서 읽어오는 데이터 양을 확장할 수 있게 됨
만약 카프카 컨슈머가 지연시간이 긴 작업을 수행하고 현재 컨슈머가 토픽에 들어오는 데이터의 속도를 감당할 수 없다면, 컨슈머를 추가함으로써 단위 컨슈머가 처리하는 파티션과 메시지의 수를 분산시켜서 규모 확장을 할 수 있음
이때 토픽을 생성할 때 파티션 수를 크게 잡아주어 부하가 증가함에 따라 더 많은 컨슈머를 추가할 수 있도록 함
새로운 컨슈머 그룹을 추가하면 기존에 다른 컨슈머 그룹과는 상관없이 전체 메시지를 받을 수 있음
컨슈머 그룹과 파티션 리밸런스
리밸런스 : 컨슈머에 할당된 파티션을 다른 컨슈머에게 할당해 주는 작업
- 특정 컨슈머가 종료되거나 크래시 났을 경우 이 컨슈머가 읽던 파티션들은 그룹에 있는 나머지 컨슈머 중 하나가 대신 할당받아서 읽어야 함
- 컨슈머 그룹이 읽고 있는 토픽이 변경되었을 때도 발생(토픽에 새 파티션을 추가했을 경우)
- 새로운 컨슈머가 추가되었을 경우
리밸런스 프로토콜 :
(출처: https://www.confluent.io/blog/cooperative-rebalancing-in-kafka-streams-consumer-ksqldb/)
단일 consumer 가 group leader 로 선택되게 됨 .. 위 사진에서는 먼저 조인한 consumer C가 group leader
rebalance 는 2 phase 로 이뤄지게 됨
- 그룹 코디네이터는 각 멤버가 그룹에 가입할 때까지 기다림. 각 컨슈머는 JoinGroup 요청을 보내 관심 topic과 client-defined 유저 데이터를 포함하는 subscription 을 인코딩함. subscription 은 브로커에 의해 통합되어 JoinGroup 응답으로 그룹 리더에게 전송됨.
- 리더는 구독을 디코딩한다음 파티션 할당을 계산하고 인코딩하여 SyncGroup 요청에서 그룹 코디네이터에게 전송함. 이때 파티션 할당 정책에서는 PartitionAssignor 인터페이스 구현체가 사용됨. 파티션 할당이 결정되면 그룹 리더는 할당 내용을 그룹 코디네이터에게 전달하고, 그룹 코디네이터는 이 정보를 컨슈머에게 전파함 모든 컨슈머는 브로커에게 SyncGroup 요청을 보내야 함. 브로커는 SyncGroup 응답에서 파티션 할당을 보내게 됨 ..
전체 rebalance 기간 동안 각 consumer는 서로 직접 통신하는게 아님, 브로커 측 그룹 코디네이터를 매개해 서로에게 정보를 전파함
조급한 리밸런스 (Eager rebalance)
(출처: https://www.confluent.io/blog/cooperative-rebalancing-in-kafka-streams-consumer-ksqldb/)
조급한 리밸런스는 모든 컨슈머가 읽기 작업을 멈추고 자신에게 할당된 모든 파티션에 대한 소유권을 포기한 뒤, 컨슈머 그룹에 다시 참여하여 완전히 새로운 파티션 할당을 전달받음
- 각 컨슈머는 JoinGroup 요청을 보내기 전에 자신에게 할당된 파티션에 대한 소유권을 포기하고, 리밸런스에 참여한다
- 그 결과 Synchrnoization barrier(동기화 장벽) 이 적용됨
- JoinGroup 응답이 리더에게 보내질 때 모든 파티션은 소유권이 회수된 상태며, partition assignor는 이걸 분배할 수 있게 됨
BUT “stop-the-world” 문제가 발생
- rebalance 가 진행되는 동안 그룹의 어떤 컨슈머도 작업을 처리할 수 없음
- rebalance 진행 시간은 각 컨슈머가 모든 파티션을 취소한 다음 다시 시작해야 되므로 파티션 수에 따라 늘어나게 됨
협력적 리밸런스(Cooperative rebalance)
재할당이 필요한 partition 만 revoke 하고 다시 할당하면 되지 않아? 라는 아이디어 그러면 전체가 멈출 필요 없이 다운타임은 오직 재할당 파티션을 revoke 하는데 걸리는 시간만큼만 걸릴거임
⇒ 만약 이렇게 하려면 파티션을 consumer A에서 consumer C로 마이그레이션 할려면 C는 A가 소유권을 포기할 때까지 기다려야 파티션을 가져갈 수 있음. BUT C는 A가 파티션 해지를 완료한 시점을 알 수 없다(=재할당하기 안전한 시점을 알 수 있는 방법이 없다), consumer는 rebalance 중에만 통신할 수 있다 .. 그러면 연속으로 2번 리밸런싱하면 어떨까? 라는 아이디어
(출처: https://www.confluent.io/blog/cooperative-rebalancing-in-kafka-streams-consumer-ksqldb/)
2단계에 거쳐서 수행
- 모든 컨슈머 멤버가 JoinGroup 요청을 보냄, 그룹 코디네이터는 subscriptions 을 그룹 리더에게 보내고, 컨슈머 그룹 리더가 다른 컨슈머들에게 각자에게 할당된 파티션 중 일부가 재할당 될 것이라고 통보(현재 소유하고 있는 취소될 파티션을 제외한 새로운 할당이 각 멤버에게 전달됨) 하면, 각 컨슈머는 새로운 할당에 나타나지 않는 모든 파티션에 대해 데이터를 읽어오는 작업을 멈추고 소유권을 포기함
- 컨슈머 그룹 리더가 소유권이 포기된 파티션들을 새로 할당하게 됨
컨슈머 그룹에 컨슈머 수가 많은 경우 리밸런싱 작업에 상당한 시간이 걸릴 위험이 있는데, 이 경우 stop-the-world 되지 않게 함
파티션에 대한 컨슈머의 소유권을 어떻게 알 수 있나?: 컨슈머는 해당 컨슈머 그룹의 그룹 코디네이터 역할을 지정받은 카프카 브로커에게 하트비트 를 전송함으로써 멤버십과 할당된 파티션에 대한 소유권을 유지함
하트비트는 백그라운드 스레드에 의해 전송되고, 일정한 간격을 두고 전송되는 한 연결이 유지되는 것으로 간주
일정 시간동안 하트비트를 전송하지 않으면 세션 타임아웃 이 발생하면서 컨슈머가 죽었다고 간주하고, 리밸런스가 실행 됨
정적 그룹 멤버십
일반적으로, 컨슈머가 갖는 컨슈머 그룹의 멤버로서의 자격은 일시적임.
컨슈머가 컨슈머 그룹을 떠나는 순간 해당 컨슈머에 할당되어있는 파티션들은 해제되고 다시 참여할 경우 새로운 멤버ID가 발급되면서 리밸런스 프로토콜에 의해 새로운 파티션이 할당되게 됨.
컨슈머에 고유한 group.instance.id 값을 잡아주면 해당 컨슈머가 컨슈머 그룹의 정적인 멤버가 되도록 해줌. 해당 컨슈머가 컨슈머 그룹에 참여하면, 평소와 같이 파티션 할당 전략에 따라 파티션이 할당되고 session timeout이 경과되어 그룹을 떠나고 이후 다시 그룹에 조인하면 멤버십이 그대로 유지 되기 때문에, 리밸런스가 발생할 필요 없이 예전에 할당받았던 파티션을 그대로 재할당받음
그룹 코디네이터가 각 멤버에 대한 파티션 할당을 캐시해 두고 있기 때문에 다시 조인해 들어와도 리밸런스 발생 X
언제 사용되나?: 애플리케이션이 각 컨슈머에 할당된 파티션의 내용물을 사용해서 로컬 상태나 캐시를 유지해야 될 때. (컨슈머가 재시작 할 때마다 다시 상태를 setup 하거나 캐시를 재생성하는 것이 시간이 오래 걸린다면 이 작업을 반복하고 싶지는 않을 것)
주의점?:
파티션을 할당받은 컨슈머가 재시작 했을 때 그간 처리되지 않았던 메시지를 따라잡을 수 있는지 체크해야 함. 각 컨슈머에 할당된 파티션들이 다른 컨슈머들로 재할당 되지 않기 때문에, 정지되어 있던 지정된 컨슈머가 다시 돌아오면 이 파티션에 저장된 최신 메시지에서 한참 밀린 메시지부터 처리하게 되기 때문임.
`
- 단순한 애플리케이션 재시작이 리밸런싱을 작동시키지 않을 만큼 충분히 크면서
- 만약 작동이 멈출 경우 자동으로 파티션 재할당이 이루어져서 오랫동안 파티션 처리가 멈추는 상황을 막을 수 있을 만큼 충분히 작은 값으로 설정해야 함.
카프카 컨슈머 구현
서버에 추가 데이터가 들어왔는지 폴링하는 단순한 루프
public class ConsumerDemo {
private static final Logger log = LoggerFactory.getLogger(ConsumerDemo.class.getSimpleName());
public static void main(String[] args) {
log.info("I am a Kafka Consumer");
//create Producer Properties
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092"); //connect to localhost
properties.setProperty("group.id", "CountryConter");
//set Producer properties
properties.setProperty("key.deserializer", StringDeserializer.class.getName());
properties.setProperty("value.deserializer", StringDeserializer.class.getName());
//create the Consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
//subsribe to topics
consumer.subscribe(Collections.singletonList("CustomerCountry"));
Duration timeout = Duration.ofMillis(100);
Map<String, Integer> custCountryMap = new HashMap<>();
//polling loop
while (true){
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records){
System.out.printf("topic = %s, partition = %d, offset = %d, customer = %s, " +
"country = %s",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
int updatedCount = 1;
if (custCountryMap.containsKey(record.value())){
updatedCount = custCountryMap.get(record.value()) + 1;
}
custCountryMap.put(record.value(), updatedCount);
}
}
}
}
- poll(timeout) : 컨슈머가 카프카를 계속해서 폴링하지 않으면 죽은 것으로 간주되어 컨슈머가 읽어오고 있던 파티션들은 다른 컨슈머에게 넘겨짐 poll의 timeout 매개변수는 컨슈머 버퍼에 데이터가 없을 경우 poll이 블록될 수 있는 최대 시간 결정
- poll() 은 레코드들이 저장된 List 객체 리턴, 각 토픽, 파티션, 오프셋 , 키, 밸류 값이 포함됨
새 컨슈머에서 처음으로 poll() 을 호출하면 컨슈머는 그룹 코디네이터를 찾아서 컨슈머 그룹에 참가하고 파티션을 할당받음. 리밸런스도 여기서 처리됨.
poll이 max.poll.interval.ms 에 지정된 시간 이상으로 호출되지 않을 경우 컨슈머는 죽은 것으로 간주되어 컨슈머 그룹에서 퇴출, 즉 각 ==각 폴링 루프 안에서 긴 시간 blocking 되는 작업은 지양
스레드 안정성
1 thread 당 1 consumer
각 메시지를 여러 스레드가 처리하게 할 경우 다음과 같은 문제가 발생할 수 있음
- record가 프로세싱 되기 전 오프셋이 커밋 될 수 있음
- 같은 파티션 내 메시지는 병렬적으로 처리되기 때문에 message 처리 순서가 보장되지 않음
1 application 에서 동일한 그룹에 속하는 여러개의 컨슈머를 운용하고 싶다면,
- ExecutorService 를 사용해서 각자의 컨슈머를 가지는 다수의 스레드를 시작
- 이벤트를 받아서 큐에 넣는 컨슈머 하나와 이 큐에서 이벤트를 꺼내서 처리하는 여러 개의 워커 스레드로 구성
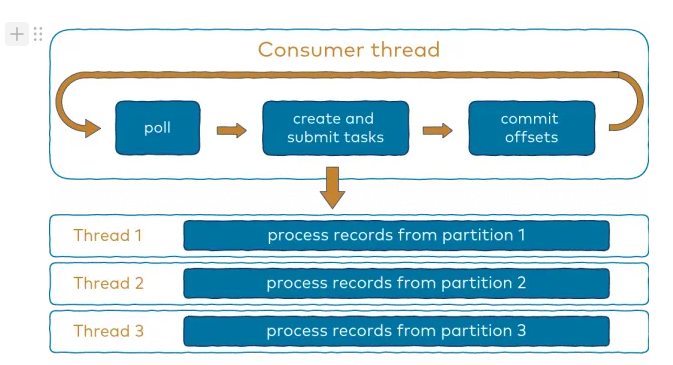
(출처: https://www.confluent.io/blog/kafka-consumer-multi-threaded-messaging/)
각 파티션마다 thread 1개씩 할당해서 멀티 스레드로 동시적으로 처리하는 예제 ..
public void run() {
try {
consumer.subscribe(Collections.singleton("topic-name"), this);
while (!stopped.get()) { //records를 polling 받음
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
handleFetchedRecords(records);
checkActiveTasks();
commitOffsets();
}
} catch (WakeupException we) {
if (!stopped.get())
throw we;
} finally {
consumer.close();
}
}
//record processing task 를 생성하고 threadPool 에 제출함
private void handleFetchedRecords(ConsumerRecords<String, String> records) {
if (records.count() > 0) {
records.partitions().forEach(partition -> {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
Task task = new Task(partitionRecords);
executor.submit(task);
activeTasks.put(partition, task);
});
consumer.pause(records.partitions());
}
}
//각 task 가 완료되었는지 체크하고 완료되었다면 해당 태스크 activeTaskMap 에서 제거
private void checkActiveTasks() {
List finishedTasksPartitions = new ArrayList<>();
activeTasks.forEach((partition, task) -> {
if (task.isFinished())
finishedTasksPartitions.add(partition);
long offset = task.getCurrentOffset();
if (offset > 0)
offsetsToCommit.put(partition, new OffsetAndMetadata(offset));
});
finishedTasksPartitions.forEach(partition -> activeTasks.remove(partition));
consumer.resume(finishedTasksPartitions);
}
//offset commit (every iteration 마다 커밋하지 않음, 너무 많은 commit request 가 쌓이는 것을
//방지하기 위함. 일정 시간이 지난 이후에 한번에 commit
private void commitOffsets() {
try {
long currentTimeMillis = System.currentTimeMillis();
if (currentTimeMillis - lastCommitTime > 5000) {
if(!offsetsToCommit.isEmpty()) {
consumer.commitAsync(offsetsToCommit);
offsetsToCommit.clear();
}
lastCommitTime = currentTimeMillis;
}
} catch (Exception e) {
log.error("Failed to commit offsets!", e);
}
}
컨슈머 설정값
fetch.min.bytes
컨슈머가 브로커로부터 레코드를 얻어올 때 받는 데이터의 최소 바이트
브로커가 컨슈머로부터 요청 받았는데 새로 보낼 레코드 양이 fetch.min.bytes 보다 작을 경우 충분한 메시지 보낼 수 있을 때까지 기다림
이 설정은 토픽에 새로운 메시지가 들어오지 않거나 쓰기 요청이 적은 시간대일 때 오가는 메시지 수를 줄임으로써 컨슈머, 브로커 양쪽의 부하를 줄여줌
fetch.max.wait.ms
카프카가 컨슈머에게 응답하기 전 충분한 데이터가 모일 때까지 얼마나 오래 기다릴 것인지 결정
잠재적인 지연을 제한하고 싶을 경우 이 값을 더 작게 잡아주면 됨
카프카는 fetch.min.bytes, fetch.max.wait.ms 둘 중 하나가 만족되는 데로 레코드를 리턴하게 됨
fetch.max.bytes
컨슈머가 브로커를 폴링할 때 카프카가 리턴하는 최대 바이트 수 지정
컨슈머가 서버로부터 받은 데이터를 저장하기 위해 사용하는 메모리 양을 제한하기 위해 사용
브로커가 보내야 하는 첫 번째 레코드 배치의 크기가 이 설정값 넘길 경우 제한 값 무시하고 해당 배치 그대로 전송 , 이건 컨슈머가 읽기 작업을 계속 진행할 수 있도록 보장
따라서 이 값은 절대적인 최대값 아니고 브로커가 허용하는 최대 레코드 일괄 처리 크기는 message.max.bytes(broker config) 또는 max.message.bytes(topic config)를 통해 정의됨
max.poll.records
poll() 을 호출할 때 마다 리턴되는 최대 레코드 개수
max.partition.fetch.bytes
서버가 파티션 별로 리턴하는 최대 바이트 수
하지만 브로커가 보내온 응답에서 얼마나 많은 파티션이 포함되어 있는지를 결정할 수 있는 방법이 없기 때문에 이 설정을 사용하기 보단 fetch.max.bytes 를 사용하자.
session.timeout.ms, heartbeat.interval.ms
컨슈머가 그룹 코디네이터에게 하트비트를 보내지 않은 채로 session.timeout.ms 가 지나면 그룹 코디네이터는 해당 컨슈머가 죽은 것으로 간주, 리밸런싱 실행
이 속성은 카프카 컨슈머가 얼마나 자주 그룹 코디네이터에게 하트비트를 보낼 건지 결정하는 hearbeat.interval.ms 속성과 관련 .. 두 속성은 주로 같이 변경됨 (하트비트는 세션 타임아웃보다 더 낮은 값이여야 하며, 대체로 1/3 으로 결정됨)
session.timeout.ms 를 기본값(45초) 보다 낮게 잡을 경우 죽은 컨슈머를 빨리 찾아낼 수 있으나 그만큼 원치 않은 리밸런싱이 자주 초래될 수 있음
max.poll.interval.ms
컨슈머가 폴링을 하지 않고도 죽은 것으로 판정되지 않을 수 있는 최대 시간
하트비트는 백그라운드 스레드에 의해 전송되는데 만약 카프카에서 레코드를 읽어오는 메인 스레드는 데드락이 걸렸는데 백그라운드 스레드는 하트비트를 전송할 수 있다 .. 이 경우 방지하기 위함
또한 리턴된 레코드 각각에 대해 시간이 오래 걸리는 처리를 해야 하는 애플리케이션의 경우, 리턴되는 데이터 양을 제한하기 위해서도 사용됨.
타임아웃 발생 시 백그라운드 스레드는 리밸런스가 수행하도록 하기 위해 leave group 요청 보낸 뒤 하트비트 전송을 중단함
request.timeout.ms
컨슈머가 브로커로부터 응답을 기다릴 수 있는 최대 시간
이 시간 안에 응답하지 않을 경우 클라이언트는 연결 닫은 후 재 연결 시도함, 연결 끊기 전 브로커에게 요청 처리할 시간을 충분히 줘야 함
auto.offset.reset
컨슈머가 예전에 오프셋을 커밋한 적이 없거나, 커밋된 오프셋이 유효하지 않을 때(커밋한 오프셋의 레코드가 이미 브로커에서 삭제된 경우) 파티션을 읽기 시작할 때 작동을 정의
디폴트는 latest (⇒ 컨슈머 작동 시작부터 쓰여지기 시작한 레코드) 이나, earliest 도 있음(파티션의 맨 처음부터 쓰여진 레코드를 읽음)
partition.assignment.strategy
PartitionAssignor의 파티션 할당 전략을 결정
- Range: 컨슈머가 구독하는 각 토픽의 파티션들을 연속된 그룹으로 나눠서 할당. 각 토픽의 파티션 수가 컨슈머 수로 깔끔하게 나누어떨어지지 않는 상황에서 첫 번째 컨슈머가 두번째 컨슈머보다 더 많은 파티션을 할당 받을 수 있음
- RoundRobin: 모든 구독된 토픽의 모든 파티션을 가져다 순차적으로 하나씩 컨슈머에 할당. 모든 컨슈머들이 거의 완전히 동일한 수의 파티션을 할당받게 됨.
- Sticky: 파티션들을 가능한 균등하게 할당 & 리밸런스가 발생 시 가능하면 많은 파티션들이 같은 컨슈머에 할당되게 함 (파티션이 다른 컨슈머로 옮겨질 때 발생하는 오버헤드 최소화)
- Cooperative Sticky: 스티키와 기본적으로 동일, 컨슈머가 재할당되지 않은 파티션으로부터 레코드를 계속해서 읽어올 수 있도록 하는 협력적 리밸런스 기능 지원
client.rack
클라이언트가 위치한 영역을 식별하여 컨슈머가 가장 가까운 레플리카로부터 읽어올 수 있게하는 설정
offsets.retention.minutes
브로커 설정임. 카프카가 커밋된 오프셋을 얼마 동안 보관할 건지 결정
커밋된 오프셋이 삭제된 상태에서 컨슈머 그룹이 다시 활동을 시작하면 완전히 새로운 컨슈머 그룹처럼 작동
오프셋과 커밋
오프셋 커밋: 파티션의 현재 위치를 업데이트 하는 작업
레코드를 개별적으로 커밋하는게 아니라 파티션에서 성공적으로 처리해 낸 마지막 메시지를 커밋함으로써 그 앞의 모든 메시지가 성공적으로 처리되었음을 암묵적으로 나타냄
카프카에 특수 토픽인 __consumer_offsets 토픽에 각 파티션 별로 커밋된 오프셋들을 업데이트하는 메시지를 보냄
만약 리밸런스가 발생해서 새로운 컨슈머가 파티션을 할당받으면, 어디서부터 작업을 재개해야 될 지 알아내기 위해 컨슈머는 각 파티션의 마지막으로 커밋된 메시지를 읽어온 후 거기서부터 재개할 수 있음
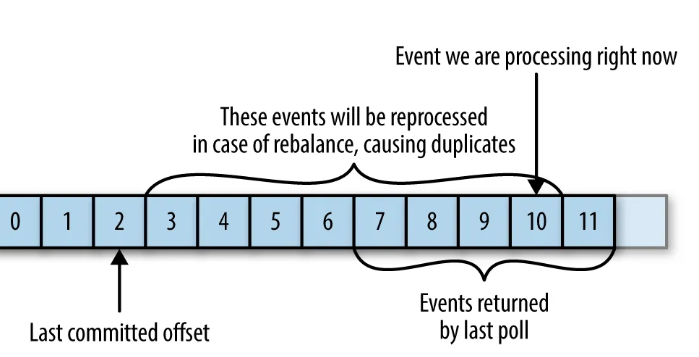
만약 커밋된 오프셋이 클라이언트가 처리한 마지막 오프셋보다 작을 경우,
그 사이 메시지들은 중복되서 처리될 수 있음
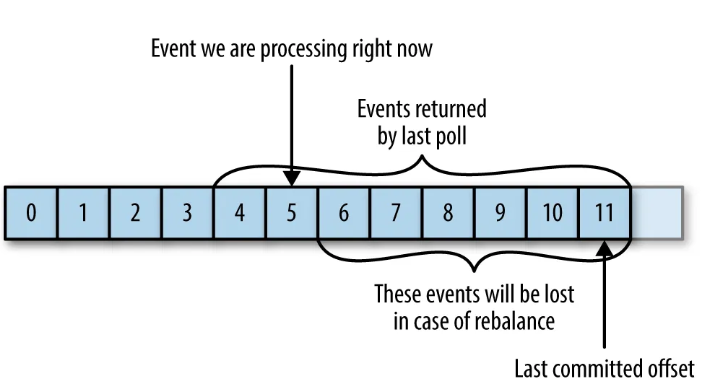
커밋된 메시지가 클라이언트가 실제로 처리한 메시지보다 클 경우,
그 사이의 메시지는 누락되게 됨
자동 커밋
enable.auto.commit 설정을 true 로 잡아주면, 컨슈머는 5초에 한번(⇒ auto.commit.interval.ms 로 조정 가능) , poll() 메서드를 실행할 때마다 컨슈머는 커밋해야 되는지 확인한 뒤 그러할 경우 마지막 poll() 호출에서 리턴된 오프셋을 커밋
만약 마지막으로 커밋된 지 3초 후에 크래시가 발생해서 리밸런싱 후 남은 컨슈머들이 마지막으로 커밋된 오프셋부터 작업을 시작하면, 크래시되기 전 3초 전까지 읽혔던 레코드는 중복되서 처리됨
poll() 호출 전 이전 호출에서 리턴된 모든 이벤트를 처리하는게 중요함 . 그러지 않으면 일부 이벤트가누 누락될 수 있음.
따라서 메시지 유실의 가능성을 제거하고 리밸런스 발생 시 중복되는 메시지 수를 줄이기 위해
오프셋이 커밋되는 시간을 제어해야 함 (⇒ enable.auto.commit=false)
동기적 커밋
//polling loop
while (true){
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records){
System.out.printf("topic = %s, partition = %d, offset = %d, customer = %s, " +
"country = %s",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
int updatedCount = 1;
if (custCountryMap.containsKey(record.value())){
updatedCount = custCountryMap.get(record.value()) + 1;
}
custCountryMap.put(record.value(), updatedCount);
}
try{
consumer.commitSync();
} catch (CommitFailedException e) {
log.error("commit failed", e);
}
}
- commitSync() : poll 이 리턴한 마지막 오프셋을 커밋함. poll() 에서 리턴된 모든 메시지의 처리가 완료된 후 호출해야 함. BUT 브로커가 커밋 요청에 응답할 때까지 애플리케이션이 블록됨. 애플리케이션 처리량을 제한하게 됨. 덜 커밋할 경우 잠재적인 중복 메시지의 수는 늘어난다.
비동기적 커밋
브로커가 커밋에 응답할 때까지 기다리는 동안 대신 요청만 보내고 처리를 계속함
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
if (e != null){
log.error("commit failed");
}
}
});
- commitAsync : 재시도를 하지 않음. 서버로부터 응답을 받은 시점에 이미 다른 커밋 시도가 성공했을 수 있기 때문이다. 오프셋 2000을 보냈는데 브로커가 응답하지 못했지만, 그 이후 성공적으로 오프셋 3000에 대한 응답을 받을 때 오프셋 2000을 재시도 하게 되면 오프셋 3000까지 커밋된 이후에 오프셋 2000을 커밋되는 경우가 발생할 수 있다 ..
만약 비동기적 커밋을 재시도 하려면, 커밋할 때마다 번호를 1씩 증가시킨 후 콜백에 해당 번호를 넣어주고 이후 재시도 요청을 보낼 준비가 되었을 때 해당 번호와 해당 변수의 현재 값을 비교한 후 해당 번호의 값이 더 크다면 재시도를 해도 된다
일반적으로는 커밋 실패가 큰 문제가 되지 않지만,
컨슈머를 닫기 전 혹은 리밸런스 전 마지막 커밋이라면 성공 여부를 확인해야 함
이때 commitAsync 와 commitSync 를 함께 사용할 수 있다.
일반적인 상황에서는 blocking 되지 않는 비동기 commit 을 사용하지만
컨슈머를 닫는 상황에서는 다음 커밋이 있을 수 없으므로 commitSync 를 호출해서 커밋 성공하거나 회복 불가능한 에러가 발생할 때까지 재시도해야 함
while (true){
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records){
System.out.printf("topic = %s, partition = %d, offset = %d, customer = %s, " +
"country = %s",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
currentOffsets.put(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset()+1, "no metadata") //현재 레코드의 오프셋 + 1을 기록
);
if (count % 1000 == 0){
consumer.commitAsync(currentOffsets, null);
}
count++;
}
}
특정 오프셋을 커밋할 수도 있음
실제 애플리케이션에는 시간 혹은 레코드 내용물 기준으로 커밋해야 할 것
리밸런스 리스너
컨슈머는 종료하기 전이나 리밸런싱이 시작되기 전에 해당 파티션에서 마지막으로 처리한 이벤트의 오프셋을 커밋하고, 파일 핸들이나 데이터베이스 연결 등을 닫아줘야 하는 cleanup 작업이 필요함
컨슈머API는 파티션이 할당되거나 해제될 때 사용자의 코드가 실행되도록 하는 매커니즘 제공
//ConsumerDemo.java
//create the Consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
ConsumerRebalanceListenerImpl listener = new ConsumerRebalanceListenerImpl(consumer);
//subsribe to topics
consumer.subscribe(Collections.singletonList("CustomerCountry"), listener);
...
//ConsumerRebalanceListenerImpl.java
public class ConsumerRebalanceListenerImpl implements ConsumerRebalanceListener {
private static final Logger log = LoggerFactory.getLogger(ConsumerRebalanceListenerImpl.class.getSimpleName());
private KafkaConsumer<String, String> consumer;
private Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
public ConsumerRebalanceListenerImpl(KafkaConsumer<String, String> consumer) {
this.consumer = consumer;
}
//현재 처리한 레코드의 offset 저장
public void addOffsetToTrack(String topic, int partition, long offset){
currentOffsets.put(
new TopicPartition(topic, partition),
new OffsetAndMetadata(offset + 1, null));
}
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
log.info("onPartitionsRevoked callback triggered");
log.info("Committing offsets: " + currentOffsets);
consumer.commitSync(currentOffsets);
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
log.info("onPartitionsAssigned callback triggered");
}
// this is used when we shut down our consumer gracefully
public Map<TopicPartition, OffsetAndMetadata> getCurrentOffsets() {
return currentOffsets;
}
}
- void onPartitionsAssigned(Collection<TopicPartition> partitions) : 파티션이 컨슈머에게 재할당된 후에 컨슈머가 메시지 읽기 시작하기 전에 호출됨 준비 작업을 수행하고, 여기서 수행되는 모든 작업은 poll.timeout.ms 내에 수행되어야 함
- void onPartitionsRevoked(Collection<TopicPartition> partitions) : 컨슈머가 할당되었던 파티션이 할당 해제될 때 호출. 협력적 리밸런스 알고리즘이 사용되었을 경우 이 메서드는 리밸런스가 완료될 때 컨슈머에서 할당 해제되어야 할 파티션들에 대해서만 호출. 오프셋을 커밋해주어야 이 파티션을 다음에 할당받는 컨슈머가 시작할 지점 알아낼 수 있음.
- void onPartitionsLost(Collection<TopicPartition> partitions) : 예외적인 상황에서 호출. 주어진 파티션들은 이 메서드가 호출되는 시점에서 이미 다른 컨슈머에게 할당되어 있는 상태
폴링 루프를 벗어나는 방법
poll() loop를 벗어나고 싶다면 ..
- 다른 스레드에서 consumer.wakeup() 호출: 대기중이던 poll() 이 WakeupException 발생시키며 중단되거나, 대기중 아닐때는 poll() 이 호출될 때 예외가 발생. 이때 스레드를 종료하기 전 consumer.close() 를 호출해주어 그룹 코디네이터에게 그룹을 떠난다는 메시지 전송하여 세션 타임아웃 기다릴 필요 없이 즉시 리밸런싱을 실행하도록 함
- 메인 스레드에서 컨슈머 루프가 돌고 있다면 ShutdownHook 사용
final Thread mainThread = Thread.currentThread();
// ShutdownHook은 별개의 스레드에서 실행됨.
// 폴링 루프를 탈출시키기 위해 wakeup() 메서드를 호출
Runtime.getRuntime().addShutdownHook(new Thread() {
public void run() {
System.out.println("Starting exit...");
movingAvg.consumer.wakeup();
try {
mainThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
try {
movingAvg.consumer.subscribe(Collections.singletonList(topic));
while (true) {
ConsumerRecords<String, String> records = movingAvg.consumer.poll(1000);
System.out.println(System.currentTimeMillis() + " -- waiting for data...");
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s\\n", record.offset(), record.key(), record.value());
int sum = 0;
try {
int num = Integer.parseInt(record.value());
buffer.add(num);
} catch (NumberFormatException e) {
// just ignore strings
}
for (Object o : buffer) {
sum += (Integer) o;
}
if (buffer.size() > 0) {
System.out.println("Moving avg is: " + (sum / buffer.size()));
}
}
for (TopicPartition tp: movingAvg.consumer.assignment())
System.out.println("Committing offset at position:" + movingAvg.consumer.position(tp));
movingAvg.consumer.commitSync();
}
//다른 스레드에서 wakeup을 호출할 경우 폴링 루프에서 wakeupException 발생
} catch (WakeupException e) {
// ignore for shutdown
//컨슈머를 종료하기 전에 리소스를 정리 및 close() 처리하여 코디네이터에게 leaving group 알림
} finally {
movingAvg.consumer.close();
System.out.println("Closed consumer and we are done");
}
}
디시리얼라이저
카프카 컨슈머는 카프카로부터 받은 바이트 배열을 자바 객체로 변환하기 위한 디시리얼라이저 필요
Avro Deserializer ..
독립 실행 컨슈머
하나의 컨슈머가 토픽의 모든 파티션으로부터 모든 테이터를 읽어와야 하거나, 토픽의 특정 파티션으로부터 데이터를 읽어와야 할 경우 (⇒ 컨슈머 그룹, 리밸런스 기능 필요 없을 경우)
아래 예시는 컨슈머 스스로가 특정 토픽의 파티션을 모두 할당한 뒤 메시지를 읽고 처리하는 예시
if (partitions != null) {
//해당 토픽에 대해 사용 가능한 파티션들을 요청
for (PartitionInfo partitionInfo : partitionInfos) {
partitions.add(new TopicPartition(partitionInfo.topic(), partitionInfo.partition()));
}
//읽고자 하는 파티션에 assign()을 호출
consumer.assign(partitions);
Duration timeout = Duration.ofMillis(100);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
log.info(
"topic: {}, partition: {}, offset: {}, customer: {}, country: {}",
record.topic(),
record.partition(),
record.offset(),
record.key(),
record.value());
}
consumer.commitSync();
}
}
주의할 점은 새로운 파티션이 토픽에 추가될 경우 알림이 오지 않는다 주기적으로 consumer.partitionsFor() 을 호출해서 파티션 정보를 확인하거나 추가될 때마다 애플리케이션을 재시작하는 방법으로 해결하자
출처: 카프카 핵심 가이드 4장
'공부 > Kafka' 카테고리의 다른 글
| 데이터 파이프라인 구축하기 (2) | 2024.12.15 |
|---|---|
| 신뢰성 있는 데이터 전달, Exactly at-once semantics (1) | 2024.11.17 |
| 카프카 내부 매커니즘 - 2 (0) | 2024.11.10 |
| 카프카 프로듀서 (0) | 2024.10.13 |
| 카프카 기본 개념 (0) | 2024.10.06 |