
티스토리 뷰
KafkaProducer Client Internals

Kafka Producer Client는 3가지 요소로 구성
- KafkaProducer: send() 를 호출함으로써 Record 를 전송
- RecordAccumulator: send() 를 호출하면 Record 가 바로 Broker에 전달되는 것이 아니라, RecordAccumulator 에 우선 저장됨. Broker 에 전달되는 것은 비동기 적으로 이루어짐
- Sender: 별도의 Sender Thread를 생성
- RecordAccumulator 에 저장된 Record를 Broker 로 전송하는 역할을 함
- Broker 응답 받으면 사용자가 설정한 콜백이 있으면 실행하고, Broker 로부터 받은 응답 결과를 Future 통해서 전달함
KafkaProducer
// create a Producer Record
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("CustomerCountry", "Precision Products", "France");
//send data and set callback
RecordMetadata recordMetadata = producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
// Message was sent successfully
System.out.println("Message sent to topic: " + metadata.topic() +
", partition: " + metadata.partition() +
", offset: " + metadata.offset());
} else {
// Handle the exception
System.err.println("Error sending message: " + exception.getMessage());
}
}
}).get();
send() 호출 시 전송할 Record, 실행 Callback 지정
send() 호출 되면 다음과 같은 작업이 이루어짐
- Serializer: 사용자로부터 전달된 Record의 Key, Value 를 Serialize
//set Producer properties
properties.setProperty("key.serializer", StringSerializer.class.getName());
properties.setProperty("value.serializer", StringSerializer.class.getName());
ByteArraySerializer, LongSerializer .. 등 여러 종류의 serializer 지정 가능
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
//...
byte[] serializedKey;
try {
serializedKey = this.keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException var21) {
ClassCastException cce = var21;
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() + " to class " + this.producerConfig.getClass("key.serializer").getName() + " specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = this.valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException var20) {
ClassCastException cce = var20;
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() + " to class " + this.producerConfig.getClass("value.serializer").getName() + " specified in value.serializer", cce);
}
//...
}
- Partitioning: 지정된 Partitioner 에 의해서 Record 가 어느 Partition 으로 갈지 결정함 Partitioner 를 지정하지 않으면 DefaultPartitioner 가 사용됨
- Key 값이 없는 경우 Round-Robin 방식으로 Partition이 할당
- Key 값이 있는 경우 Key 값의 Hash 값을 이용해서 Partition을 할당
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback){ //... int partition = this.partition(record, serializedKey, serializedValue, cluster); tp = new TopicPartition(record.topic(), partition); //... } //partitioner 에 의해 partition 지정 private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) { Integer partition = record.partition(); return partition != null ? partition : this.partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster); } - Compression: . compression.type을 설정하여 압축 시 사용할 코덱을 지정하여 압축
RecordAccumulator
//RecordAccumulator.class
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;
TopicPartiton 을 key로, Deque<ProducerBatch> 를 value 로 갖는 batches Map 존재
- TopicPartition 별로 batches 에서 deque 를 얻어옴 이때 Record 의 Serialized Size를 검사하여 buffer.memory 설정 값보다 크면 RecordTooLargeException 발생
Deque<ProducerBatch> dq = this.getOrCreateDeque(tp); //get deque according to TopicParition, or create NEW deque
synchronized(dq) {
if (this.closed) {
throw new KafkaException("Producer closed while send in progress");
}
RecordAppendResult appendResult = this.tryAppend(timestamp, key, value, headers, callback, dq, nowMs);
if (appendResult != null) {
RecordAppendResult var17 = appendResult;
return var17;
}
}
//RecordAccumulator.class
- RecordAccumulator의 append() 가 호출되면 Deque 의 Last Batch를 확인하여 key, value 를 수용할 수 있을지 확인하고 수용
- 수용 가능하면 해당 record 에 Last Batch 를 추가
- 수용 가능하지 않으면 BufferPool 에서 RecordBatch가 사용할 bytebuffer 를 받아서 새로운 Record Batch 생성 후 last에 추가, Buffer Pool 전체 사이즈는 buffer.memory 설정
- RecordBatch 생성을 위한 Buffer Size 만큼의 여유가 없으면 할당이 blocking 되고 buffer 용량이 확보될 때까지 max.block.ms 만큼만 기다림, 시간이 초과되면 TimeoutException
- RecordBatch 생성 시 사용하는 buffer size는 batch.size 설정값과 Record size 중 큰 값으로 설정됨
Sender Thread
public Map<Integer, List<ProducerBatch>> drain(Cluster cluster, Set<Node> nodes, int maxSize, long now) {
if (nodes.isEmpty()) {
return Collections.emptyMap();
} else {
Map<Integer, List<ProducerBatch>> batches = new HashMap();
Iterator var7 = nodes.iterator();
while(var7.hasNext()) { //각 broker node 들을 돌면서 record batch list 모음
Node node = (Node)var7.next();
List<ProducerBatch> ready = this.drainBatchesForOneNode(cluster, node, maxSize, now);
batches.put(node.id(), ready);
}
return batches;
}
}
private List<ProducerBatch> drainBatchesForOneNode(Cluster cluster, Node node, int maxSize, long now) {
int size = 0;
List<PartitionInfo> parts = cluster.partitionsForNode(node.id()); //node 별로 topic partition 정보 get
List<ProducerBatch> ready = new ArrayList();
int start = this.drainIndex %= parts.size();
do {
PartitionInfo part = (PartitionInfo)parts.get(this.drainIndex);
TopicPartition tp = new TopicPartition(part.topic(), part.partition());
this.drainIndex = (this.drainIndex + 1) % parts.size();
if (!this.isMuted(tp)) {
Deque<ProducerBatch> deque = this.getDeque(tp);
if (deque != null) {
synchronized(deque) {
ProducerBatch first = (ProducerBatch)deque.peekFirst(); //deque first에서 꺼냄
if (first != null) {
boolean backoff = first.attempts() > 0 && first.waitedTimeMs(now) < this.retryBackoffMs;
if (!backoff) {
if (size + first.estimatedSizeInBytes() > maxSize && !ready.isEmpty()) {
break;
}
if (this.shouldStopDrainBatchesForPartition(first, tp)) {
break;
}
boolean isTransactional = this.transactionManager != null && this.transactionManager.isTransactional();
ProducerIdAndEpoch producerIdAndEpoch = this.transactionManager != null ? this.transactionManager.producerIdAndEpoch() : null;
ProducerBatch batch = (ProducerBatch)deque.pollFirst();
if (producerIdAndEpoch != null && !batch.hasSequence()) {
this.transactionManager.maybeUpdateProducerIdAndEpoch(batch.topicPartition);
batch.setProducerState(producerIdAndEpoch, this.transactionManager.sequenceNumber(batch.topicPartition), isTransactional);
this.transactionManager.incrementSequenceNumber(batch.topicPartition, batch.recordCount);
this.log.debug("Assigned producerId {} and producerEpoch {} to batch with base sequence {} being sent to partition {}", new Object[]{producerIdAndEpoch.producerId, producerIdAndEpoch.epoch, batch.baseSequence(), tp});
this.transactionManager.addInFlightBatch(batch);
}
batch.close();
size += batch.records().sizeInBytes();
ready.add(batch); //recordBatchList 에 추가
batch.drained(now);
}
}
}
}
}
} while(start != this.drainIndex);
return ready;
}
- RecordAccumulator의 drain() 을 통해서 각 Broker 별로 전송할 RecordBatch List를 Recod Accumulator 에서 얻어옴
- 각 Node 를 돌면서 Node의 topic partition 정보를 읽어온 후 Deque<RecordBatch> 에서 first 쪽의 RecordBatch 를 꺼내서 RecordBatch List에 추가함. 이 과정을 max.request.size 설정값을 넘지 않을 때까지 모음
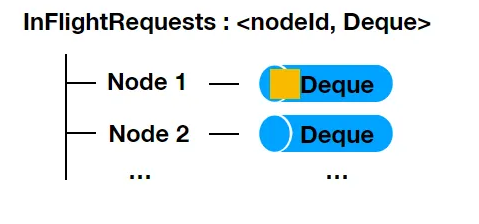
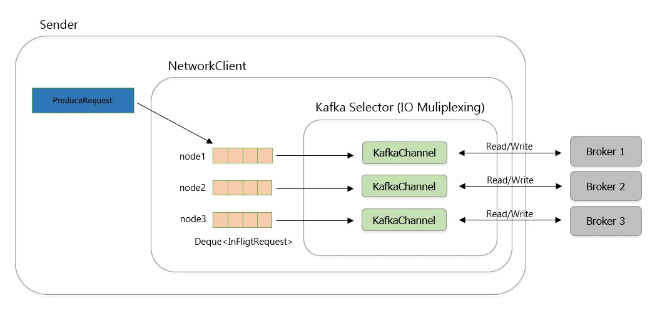
- 위 과정을 수행하면 Node 별로 전송할 RecordBatch List가 만들어지고 하나의 ProduceRequest 로 만들어져서 Broker Node에 전송됨. ProduceRequest는 InFlightRequests라는 Node 별 deque 에 먼저 저장됨.
- Broker Node 의 전송은 Sender thread에서 비동기적으로 이루어지고, Java IO Multiplexing 방식을 사용함
I/O Multiplexing
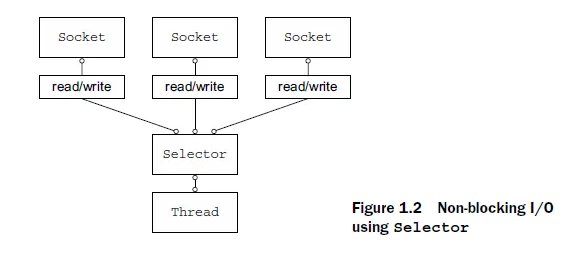
한 프로세스가 여러 파일을 관리하는 기법
파일 디스크립터(FD) 를 어떻게 감시하고 어떤 상태로 대기하느냐에 따라 select, poll, epoll 등 다양한 기법 존재
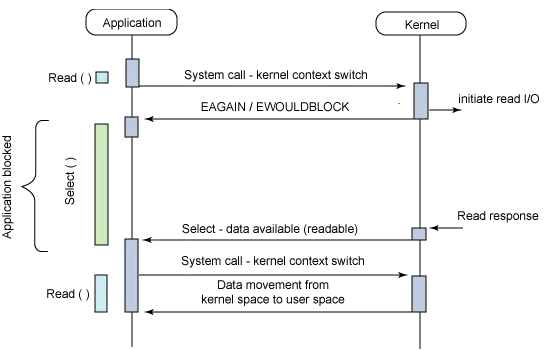
- 커널은 I/O 요청을 받아 처리를 시작하면서 동시에 사용자 프로세스에 미완료 상태를 반환, 사용자 프로세스는 데이터 준비 알림이 올 때까지 대기 여기서 read/write I/O 작업 자체가 블록되는 것이 아니라, select나 poll 같은 멀티플렉싱 관련 시스템 콜에 대한 커널의 응답이 블록되는 형태
- select() : 대상 FD를 배열에다 쭉 집어넣고 하나하나 순차 검색, 대상 FD를 배열 형태로 담고 있는 fd_set 의 비트값 하나하나 검사하여 어떤 FD에서 변경이 일어났는지 체크
- poll() : 관리 가능한 FD 수가 1024개로 제한적인 select() 와 달리 무한개의 FD 검사. 실제 FD 갯수(nfds) 만큼만 loop 돌게 됨. select() 와 마찬가지로 O(N) 의 시간 복잡도 select는 이벤트 전달에 3bit 만 사용 되지만, poll은 64bit 사용되기 때문에 FD 수 많아지면 성능이 오히려 더 떨어질 수 있음
- epoll() : O(1) 의 시간 복잡도로 수행. FD의 수가 무제한, FD 의 상태가 kernel 에서 관리되기 때문에 상태가 바뀐 것을 직접 통지함. fd_set 을 검사하기 위해 루프롤 돌 필요 없음 변화가 감지된 ‘목록’ 자체를 반환받기 때문에 대상 파일을 추가 탐색할 필요 없음
- epoll 에서는 Edge trigger, Level trigger 2 가지 방식이 존재
- Level-Trigger : 입력 buffer에 데이터가 남아있는 동안 계속해서 이벤트 등록
- Edge-Trigger: 입력 buffer에 데이터가 수신된 상황에 단 1번 이벤트 등록
- epoll_create : 입력한 size 만큼 kernel 에 공간 요청, FD 반환
- epoll_ctl: 어떤 FD 의 어떤 event를 watch 할 건지 설정
- epoll_wait: epoll_ctl 에 등록된 FD의 이벤트를 기다림
- Level-Trigger : 입력 buffer에 데이터가 남아있는 동안 계속해서 이벤트 등록
- epoll 에서는 Edge trigger, Level trigger 2 가지 방식이 존재
InFlightRequests의 Deque size는 max.in.flight.requests.per.connection 에 의해 결정되며 이것은 kafka producer 가 하나의 broker로 동시에 전송할 수 있는 요청 수를 의미함
요청이 실패할 경우 retries 설정값이 1 이상이고, max.in.flight.requests.per.connection 가 1보다 크면 순서가 바뀔 수 있음
Broker는 하나의 Connection 에 대해 요청이 들어온 순서대로 처리함, producer client는 broker로부터 응답이 오면 inflight deque의 가장 오래된 요청을 완료 처리한 후 RecordBatch 에 등록된 콜백을 실행하고 broker의 응답을 Future 통해서 사용자에게 전달함.
RecordBatch 생성할 때 쓰였던 ByteBuffer를 BufferPool 로 반환하면서 마무리됨.
KafkaConsumer Client Internals
//create Producer Properties
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092"); //connect to localhost
properties.setProperty("group.id", "CountryConter");
//set Producer properties
properties.setProperty("key.deserializer", StringDeserializer.class.getName());
properties.setProperty("value.deserializer", StringDeserializer.class.getName());
//create the Consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
ConsumerRebalanceListenerImpl listener = new ConsumerRebalanceListenerImpl(consumer);
//subsribe to topics
consumer.subscribe(Collections.singletonList("CustomerCountry"), listener);
`
Duration timeout = Duration.ofMillis(100);
Map<String, Integer> custCountryMap = new HashMap<>();
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
int count = 0;
//polling loop
while (true){
ConsumerRecords<String, String> records = consumer.poll(timeout);
//..
}
- kafka consumer에서 group.id 에 컨슈머 그룹 ID 설정하고, subscribe에 구독할 토픽을 입력한 후
poll 메서드를 호출하면 kafka consumer는 컨슈머 그룹에 참여한 후 브로커로부터 데이터를 가져옴
- GroupCoordinator는 컨슈머 그룹을 관리하는 브로커 중 하나, 컨슈머 그룹의 메타데이터와 그룹을 관리함.
- 컨슈머 그룹에 새로운 컨슈머 추가되거나, 그룹에 있던 컨슈머가 제외되면 리밸런스가 발생함 리밸런스는 컨슈머의 할당된 파티션을 다른 컨슈머로 이동시키는 작업임
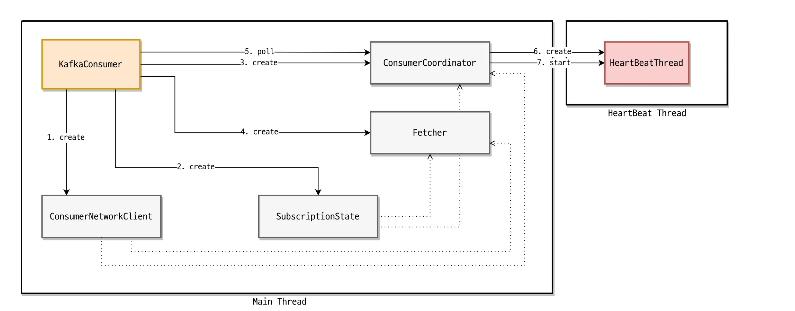
kafka consumer 의 구성요소 4가지
- ConsumerNetworkClient
- SubscriptionState
- ConsumerCoordinator (HeartBeat 스레드는 ConsumerCoordinator에 의해 생성되고, kafka consumer thread 와 별개의 스레드로 동작)
- Fetcher
ConsumerNetworkClient
ConsumerNetworkClient의 모든 요청은 비동기로 동작
ConsumerNetworkClient의 응답값은 RequestFuture 클래스로 확인
public class RequestFuture<T> {
/* 요청에 대한 처리가 끝났는지 여부 */
public boolean isDone();
/* 결과값 */
public T value();
/* 요청이 성공했는지 여부 */
public boolean succeeded();
/* 재시도가 가능한 오류인지 여부 */
public boolean isRetriable();
/* 오류가 발생했을 때 오류를 확인하는 메서드 */
public RuntimeException exception();
/* 요청이 완료 처리될 때 호출된다. complete가 호출된 이후 succeeded()가 true로 반환되고 value()를 통해 응답을 확인한다. */
public void complete(T value);
/* 요청이 실패한 경우 호출된다. */
public void raise(RuntimeException e);
/* complete 메서드가 호출되었을 때 호출될 listener를 추가한다. */
public void addListener(RequestFutureListener<T> listener);
/* RequestFuture의 응답 타입을 T에서 S로 바꿔준다. */
public <S> RequestFuture<S> compose(final RequestFutureAdapter<T, S> adapter);
}
public <S> RequestFuture<S> compose(final RequestFutureAdapter<T, S> adapter) {
final RequestFuture<S> adapted = new RequestFuture();
this.addListener(new RequestFutureListener<T>() {
public void onSuccess(T value) {
adapter.onSuccess(value, adapted);
}
public void onFailure(RuntimeException e) {
adapter.onFailure(e, adapted);
}
});
return adapted;
}
/* compose 메서드 사용 예 */
class Coordinator {
private final ConsumerNetworkClient client;
private RequestFuture<ByteBuffer> sendJoinGroupRequest() {
// send 메서드의 반환값은 RequestFuture<ClientResponse>이다.
final RequestFuture<ClientResponse> requestFuture = client.send(coordinator, requestBuilder);
// Adapter를 사용하여 RequestFuture의 타입을 ClientResponse에서 ByteBuffer로 바꾸었다.
final RequestFuture<ByteBuffer> composeResult = requestFuture.compose(new JoinGroupResponseHandler());
return composeResult;
}
}
- compose : T type 인 응답값을 S 타입으로 변환, Adapter 를 사용하여 ClientResponse → ByteBuffer 로 바꿈
- addListner : 비동기 요청이 완료되는 시점에 호출될 리스너를 지정
ConsumerNetworkClient —- NetworkClient —- Broker
- ConsumerNetworkClient 에 전달된 실제 요청은 비동기 네트워크 IO를 담당하는 NetworkClient 를 통해 이루어짐
- ConsumerNetworkClient는 전달된 모은 요청을 ClientRequest 로 만들어 NetworkClient에게 보내고, NetworkClient는 응답으로 ClientResponse를 반환
ConsumerNetworkClient 요청 처리 과정
//ConsumerNetworkClient.class
ConcurrentMap<Node, ConcurrentLinkedQueue<ClientRequest>> unsent;
public RequestFuture<ClientResponse> send(Node node, AbstractRequest.Builder<?> requestBuilder, int requestTimeoutMs) {
long now = this.time.milliseconds();
RequestFutureCompletionHandler completionHandler = new RequestFutureCompletionHandler();
//전달된 모든 요청을 ClientRequest 로 바꿈
ClientRequest clientRequest = this.client.newClientRequest(node.idString(), requestBuilder, now, true, requestTimeoutMs, completionHandler);
//내부 버퍼인 UnsentMap 에 ClientRequest 저장
this.unsent.put(node, clientRequest);
this.client.wakeup();
return completionHandler.future;
}
- KafkaConsumer의 모든 요청은 ConsumerNetworkClient의 send 메서드를 통해 시작
- ConsumerNetworkClient는 send 메서드를 통해 전달된 모든 요청을 ClientRequest로 변환하며, 요청이 완료되었을 때 호출될 RequestFuture 가 설정되어 있음 콜러는 RequestFuture를 통해 비동기 요청이 완료되었는지 확인
- ClientRequest 를 바로 전달하지 않고 내부 버퍼인 UnsetMap 에 저장, UnsetMap은 브로커 Node가 key이고 각 브로커 Node로 전달해야 될 ClientRequest 리스트가 value 임
- NetworkClient 로의 전송은 poll 메서드가 호출될 때 이루어짐
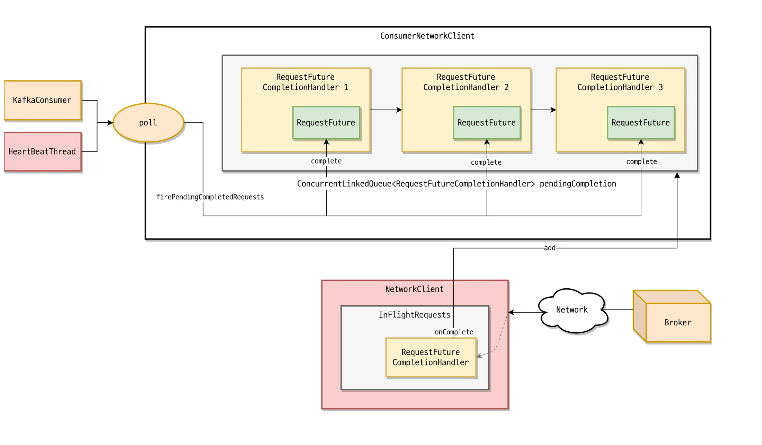
//ConsumerNetworkClient.class
private final ConcurrentLinkedQueue<RequestFutureCompletionHandler> pendingCompletion = new ConcurrentLinkedQueue();
private class RequestFutureCompletionHandler implements RequestCompletionHandler {
private final RequestFuture<ClientResponse> future;
private ClientResponse response;
private RuntimeException e;
private RequestFutureCompletionHandler() {
this.future = new RequestFuture();
}
public void fireCompletion() {
if (this.e != null) {
this.future.raise(this.e);
} else if (this.response.authenticationException() != null) {
this.future.raise(this.response.authenticationException());
} else if (this.response.wasDisconnected()) {
ConsumerNetworkClient.this.log.debug("Cancelled request with header {} due to node {} being disconnected", this.response.requestHeader(), this.response.destination());
this.future.raise(DisconnectException.INSTANCE);
} else if (this.response.versionMismatch() != null) {
this.future.raise(this.response.versionMismatch());
} else {
this.future.complete(this.response); //완료 처리
}
}
public void onFailure(RuntimeException e) {
this.e = e;
ConsumerNetworkClient.this.pendingCompletion.add(this);
}
public void onComplete(ClientResponse response) {
this.response = response;
//완료되면 response 를 래핑하여 pendingCompletion 큐에 추가
ConsumerNetworkClient.this.pendingCompletion.add(this);
}
private void firePendingCompletedRequests() {
boolean completedRequestsFired = false;
while(true) {
RequestFutureCompletionHandler completionHandler = (RequestFutureCompletionHandler)this.pendingCompletion.poll();
if (completionHandler == null) {
if (completedRequestsFired) {
this.client.wakeup();
}
return;
}
completionHandler.fireCompletion(); //complete 메서드가 호출되어 완료 처리
completedRequestsFired = true;
}
}
- poll 메서드에 대해 브로커가 응답을 주면 NetworkClient는 ConsumerNetworkClient의 내부 큐인 pendingCompletion에 send 메서드 호출 시 콜러(Caller)에게 반환된 RequestFuture를 추가
- poll 메서드가 호출될 때 firePendingCompletedRequests 가 호출되고, pendingCompletion에 있는 RequestFuture는 complete 메서드가 호출되어 완료 처리됨
SubscriptionState
- SubscriptionState는 토픽, 파티션, 오프셋 정보 관리를 담당
//SubscriptionState.class
private Set<String> subscription;
public synchronized boolean subscribe(Set<String> topics, ConsumerRebalanceListener listener) {
this.registerRebalanceListener(listener);
this.setSubscriptionType(SubscriptionState.SubscriptionType.AUTO_TOPICS);
return this.changeSubscription(topics);
}
- Kafka consumer에 토픽, 파티션 할당은 assign 메서드를 통해 이루어 지는데 사용자가 직접 assign 메서드를 호출하여 수동으로 토픽, 파티션을 할당할 경우 컨슈머 리밸런스가 이루어지지 않음
- assign 메서드를 통해 할당된 파티션은 seek 메서드를 통해 초기 오프셋 값을 설정할 수 있음
- 컨슈머 그룹 관리 기능 사용을 위해서는 subscribe 메서드를 통해 특정 토픽에 구독 요청을 해야 함. 사용자가 구독을 요청한 토픽 정보는 subscription 에 저장되고 이 정보는 컨슈머 리밸런스 과정에서 사용됨
ConsumerCoordinator
- ConsumerCoordinator 는 컨슈머 리밸런스, 오프셋 초기화, 오프셋 커밋을 담당함
- ConsumerCoordinator 내부에는 HeartBeat 스레드가 존재하여 주기적으로 그룹 코디네이터에게 HeartBeat를 전송함
컨슈머 리밸런스
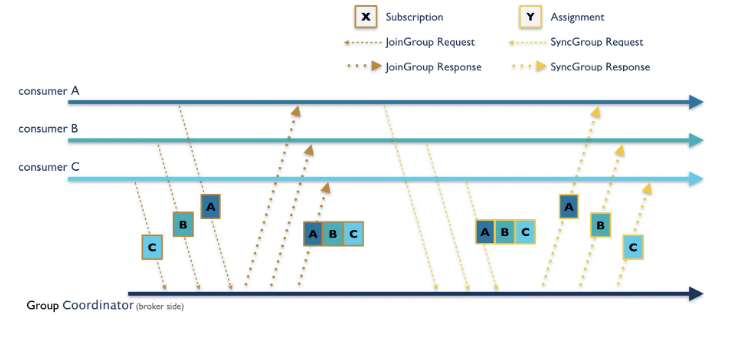
- ConsumerCoordinator는 FindCoordinator API 를 통해 JoinGroup 요청을 보낼 GroupCoordinator(그룹이 구독한 토픽, 파티션, 그룹 멤버를 관리하는 브로커) 를 찾음
- 그룹 코디네이터 호스트와 포트 정보를 응답으로 받으면 JoinGroup 요청을 그룹 코디네이터에게 보내 그룹 참여를 요청함
- groupId, sessionTimeout (이 시간 내에 heartbeat 요청을 그룹 코디네이터에게 보내지 않으면 해당 컨슈머가 죽은 것으로 판단) , rebalanceTimeout(리밸런스 발생 시 이 시간 이내에 joingroup 요청을 보내지 않으면 컨슈머가 죽은것으로 판단), groupProtocols (메타데이터; 컨슈머가 구독하려는 토픽과 컨슈머가 지원하는 파티션 할당 정책) 를 요청으로 포함함
- 응답으로는 member_id, leader_id, members .. 를 보내며 이때 member_id 와 leader_id 가 같은 컨슈머가 리더가 됨
- 이후 SyncGroup 요청을 그룹 코디네이터에게 보내고 리더는 파티션 할당 결과를 SyncGroup API 요청에 포함시키고, 그룹 코디네이터는 응답으로 각 컨슈머에게 할당된 토픽, 파티션 정보 보냄
오프셋 초기화
- OffsetFetch API : 커밋된 오프셋 가져오기요청에는 groupId, partition 이 포함되며 응답에는 해당 topic partition 에 대한 commit offset 임
- Kafka consumer는 consumer coordinator 통해 커밋된 오프셋 값 확인 그룹 코디네이터에게 커밋된 오프셋 정보를 받음
- ListOffsets API : 파티션의 오프셋 가져오기 커밋된 오프셋 정보가 없을 때 kafka consumer는 auto.offset.reset 설정에 따라 오프셋을 초기화 함, 설정에 따라 가장 마지막이나 처음 오프셋을 알기 위해서는 특정 시간에 해당하는 오프셋을 알아내는 ListOffsetAPI 를 활용 (auto.offset.reset 설정값이 earliest 인 경우 -2, latest 인 경우에는 -1 로 설정함)
오프셋 커밋
enable.auto.commit 설정이 true 인 경우 auto.commit.interval.ms 마다 오프셋을 자동으로 커밋함 수동으로 오프셋을 커밋하려면 commitSync 메서드나 commitAsync 메서드를 사용함
Fetcher
브로커로부터 데이터를 가져오는 역할을 담당하는 클래스
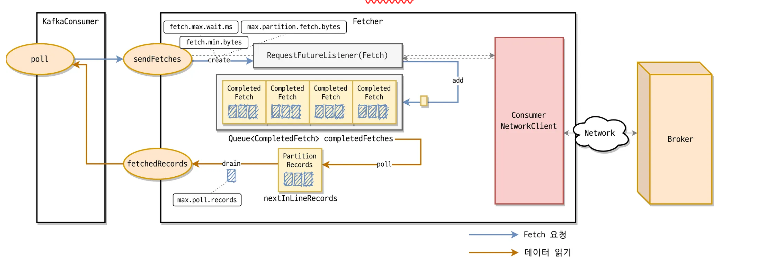
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(Timer timer) {
long pollTimeout = this.coordinator == null ? timer.remainingMs() : Math.min(this.coordinator.timeToNextPoll(timer.currentTimeMs()), timer.remainingMs());
Map<TopicPartition, List<ConsumerRecord<K, V>>> records = this.fetcher.fetchedRecords();
if (!records.isEmpty()) { //이미 가져온 데이터가 있는 경우에는 반환
return records;
} else {
this.fetcher.sendFetches(); //없으면 파티션 리더인 각 브로커에게 요청 보냄
if (!this.cachedSubscriptionHashAllFetchPositions && pollTimeout > this.retryBackoffMs) {
pollTimeout = this.retryBackoffMs;
}
this.log.trace("Polling for fetches with timeout {}", pollTimeout);
Timer pollTimer = this.time.timer(pollTimeout);
this.client.poll(pollTimer, () -> {
return !this.fetcher.hasAvailableFetches();
});
timer.update(pollTimer.currentTimeMs());
return this.fetcher.fetchedRecords();
}
}
- kafka consumer의 poll 메서드가 호출되면 Fetcher의 fetchRecords 메서드가 호출
- fetchRecords 메서드는 내부 캐시인 nextInLineFetch 와 completedFetches 를 확인하여 이미 가져온 데이터가 있는 경우 max.poll.records 설정 값만큼 레코드 반환
- 이미 가져온 데이터가 없을 경우 sendFetches 메서드 호출하여 각 파티션 리더가 위치한 Broker별로 레코드 페치 요청을 보냄 . KafkaConsumer는 Fetcher가 브로커로부터 응답을 받을 때까지 대기
- fetch.max.wait.ms: 브로커가 fetch 요청을 받았을 때 fetch.min.bytes 만큼 데이터가 없는 경우 응답을 주기까지 최대로 기다리는 시간
- fethc.min.bytes: 최소 브로커는 fetch.min.bytes 만큼 데이터가 반환해야 함
- fetch.max.bytes: 브로커가 최대 반환해야 하는 크기; 첫 번째 파티션의 첫 번째 메시지가 이 값보다 크다면 컨슈머가 계속 진행될 수 있게 하기 위해 데이터 반환
- max.partition.bytes: 브로커가 반환할 파티션 당 최대 크기
Kafka Network Internals
- NetworkClient는 Kafka 클라이언트와 브로커 노드들의 연결 상태를 관리하고 브로커 노드로 데이터를 쓰거나 브로커 노드에서 데이터를 읽는 역할을 함
- KafkaClient 인터페이스 의 구현체가 Network Client
public interface KafkaClient extends Closeable {
// 노드에 요청을 보낼 수 있는 상태인지 확인
boolean isReady(Node node, long now);
// 노드에 요청을 보낼 수 있는 상태인지 확인하고 필요한 경우 Connection 생성
boolean ready(Node node, long now);
// 다음 연결 시도까지 얼마나 기다려야 하는지 확인
long connectionDelay(Node node, long now);
// 노드로의 연결이 끊겼는지 확인
boolean connectionFailed(Node node);
// 노드로의 연결 닫기
void close(String nodeId);
// 보내야 할 요청을 큐에 저장(나중에 준비되면 요청을 전송)
void send(ClientRequest request, long now);
// 실제 I/O 수행 및 받은 응답을 가져옴
List<ClientResponse> poll(long timeout, long now);
// 가장 요청을 적게 받은 노드를 선택
Node leastLoadedNode(long now);
// 브로커로 전송되었지만 응답을 아직 받지 못한 요청들의 총합
int inFlightRequestCount();
// 특정 브로커로 전송되었지만 응답을 아직 받지 못한 요청들의 수
int inFlightRequestCount(String nodeId);
// I/O 수행을 기다리고 있는 스레드를 깨움
void wakeup();
}
ClusterConnectionStates
final class ClusterConnectionStates {
static final int RECONNECT_BACKOFF_EXP_BASE = 2;
static final double RECONNECT_BACKOFF_JITTER = 0.2;
static final int CONNECTION_SETUP_TIMEOUT_EXP_BASE = 2;
static final double CONNECTION_SETUP_TIMEOUT_JITTER = 0.2;
//각 브로커 별로 브로커의 연결 상태에 관한 정보를 기록
private final Map<String, NodeConnectionState> nodeState;
private final Logger log;
private final HostResolver hostResolver;
private Set<String> connectingNodes;
private ExponentialBackoff reconnectBackoff;
private ExponentialBackoff connectionSetupTimeout;
//..
}
private static class NodeConnectionState {
ConnectionState state;
AuthenticationException authenticationException;
long lastConnectAttemptMs;
long failedAttempts;
long failedConnectAttempts;
long reconnectBackoffMs;
long connectionSetupTimeoutMs;
long throttleUntilTimeMs;
private List<InetAddress> addresses;
private int addressIndex;
private final String host;
private final HostResolver hostResolver;
//..
}
public enum ConnectionState {
DISCONNECTED,
CONNECTING,
CHECKING_API_VERSIONS,
READY,
AUTHENTICATION_FAILED;
//..
}
- NetworkClient 는 브로커와의 연결 상태를 ClusterConnectionStates 로 관리
- 브로커와의 연결 상태에 대한 정보를 NodeConnectionState 에 저장
- 현재 연결 상태 (ConnectionState)
- 마지막으로 연결을 시도했던 시간, 연결 실패했던 시간 등의 정보가 기록
- kafka client 가 브로커와의 연결을 시도하면 connection state 는 아래 그림과 같음
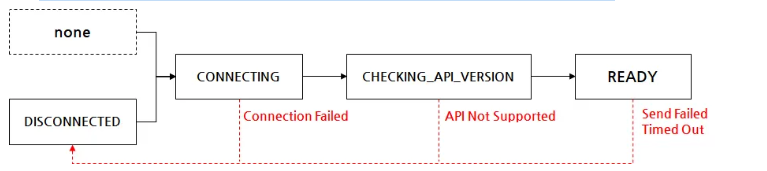
Connected 되고 API version 을 체크 후 최종적으로 READY 상태가 됨
- connection state 의 의미
- disconnected: 브로커 노드 연결 초기화 실패한 경우, 요청 전송하고 응답 기다리다 타임아웃이 발생한 경우 등으로 연결이 끊긴 상태 의미. reconnect.backoff.ms 에 설정한 시간이 지난 이후 재연결 시도. backoff 시간을 보장하기 위해서 NodeConnectionState.reconnectBackoffMs 에 마지막 연결 시간을 기록해 놓음
- connecting: kafka 클라이언트가 브로커와 연결을 시도할 때의 상태. 이때 브로커와 통신하기 위한 SocketChannel 을 생성하며 송신 버퍼의 크기는 send.buffer.bytes, 수신 버퍼의 크기는 receive.buffer.bytes 만큼 생성됨
- SocketChannel 을 생성한 이후 I/O 멀티플렉싱을 위해 Selector에 SocketChannel 을 등록하고 KafkaChannel 이 생성하는 등 네트워크 통신과 연결 관리에 필요한 객체를 생성하게 됨
- checking_api_version, ready : 연결을 위한 객체들이 생성되면 kafka client - broker 간 api version 호환성 확인 위해 kafka client 는 ApiVersionRequest 를 생성하여 브로커로 전송함. 브로커는 호환되는 버전인지 확인 후 응답을 돌려주고, 이 응답을 통해 api version 체킹 진행 문제없이 API 가 호환된다면 READY 상태가 됨
IdleExpiryManager
READY 상태로 통신할 준비가 되어있지 않은 브로커 연결을 일정 기간 사용하지 않을 경우 IdleExpiryManager에 의해 연결이 중단됨 IdleExpiryManager는 특정 SocketChannel 에 이벤트가 처리되었을 때 시간을 기록하며, 이 시간을 기준으로 LRU (Least Recently Used) 알고리즘으로 관리함
가장 오래된 브로커 연결이 connnection.max.idle.ms 설정값만큼 지난 경우 이 채널에 대해 연결을 닫고 관련 객체들을 정리함
//selector.class
private void maybeCloseOldestConnection(long currentTimeNanos) {
if (this.idleExpiryManager != null) {
Map.Entry<string, long=""> expiredConnection = this.idleExpiryManager.pollExpiredConnection(currentTimeNanos);
if (expiredConnection != null) {
//장시간 이벤트가 발생하지 않은 expired connection 에 대해
String connectionId = (String)expiredConnection.getKey();
KafkaChannel channel = (KafkaChannel)this.channels.get(connectionId);
if (channel != null) {
if (this.log.isTraceEnabled()) {
this.log.trace("About to close the idle connection from {} due to being idle for {} millis", connectionId, (currentTimeNanos - (Long)expiredConnection.getValue()) / 1000L / 1000L);
}
//ChannelState 를 EXPIRED 로 바꾸겨 연결 닫고 관련 객체를 정리함
channel.state(ChannelState.EXPIRED);
this.close(channel, Selector.CloseMode.GRACEFUL);
}
}
}
}
public Map.Entry<string, long=""> pollExpiredConnection(long currentTimeNanos) {
if (currentTimeNanos <= this.nextIdleCloseCheckTime) {
return null;
} else if (this.lruConnections.isEmpty()) {
this.nextIdleCloseCheckTime = currentTimeNanos + this.connectionsMaxIdleNanos;
return null;
} else {
Map.Entry<string, long=""> oldestConnectionEntry = (Map.Entry)this.lruConnections.entrySet().iterator().next();
//LRU 알고리즘을 적용해서 가장 Least Recently Used 한 Connection 에 대해
Long connectionLastActiveTime = (Long)oldestConnectionEntry.getValue();
// [connnection.max.idle.ms](<http://connnection.max.idle.ms>) 설정값 만큼 지난 경우 그 연결을 반환한다
this.nextIdleCloseCheckTime = connectionLastActiveTime + this.connectionsMaxIdleNanos;
return currentTimeNanos > this.nextIdleCloseCheckTime ? oldestConnectionEntry : null;
}
}
</string,></string,></string,>InflightRequests
final class InFlightRequests {
//브로커마다 전송할 수 있는 최대 요청
private final int maxInFlightRequestsPerConnection;
//브로커 별 브로커로 전송한 요청 Deque에 저장
private final Map<String, Deque<NetworkClient.InFlightRequest>> requests = new HashMap();
private final AtomicInteger inFlightRequestCount = new AtomicInteger(0);
//..
}
- Kafka client 는 성능 향상을 위해 이전에 보낸 요청에 대한 응답을 받기 전 다음 요청을 브로커로 전송할 수 있게 하는 InflightRequest 를 수행함
- NetworkClient 는 각 브로커 별로 브로커에 전송한 요청을 Deque 에 저장하는데, 브로커마다 전송할 수 있는 최대 요청은 max.in.fight.requests.per.connection 에 따라 결정됨
- 만약 브로커로부터 응답이 도착하면 Deque 에서 요청 제거한 후 응답을 처리하고, 응답에 오류 있다면 Deque 앞에 있던 요청을 Deque 맨 뒤에 다시 넣고 브로커에 재전송하게 됨 이때 max.in.fight.requests.per.connection 이 1보다 크고 retry 를 시도하게 되면 전송 순서가 바뀔 수 있음
Selector
각 Channel 마다 전담 Thread 를 생성하는 것은 리소스 낭비가 심하며 공유 자원에 대한 동기화 이슈가 발생할 수 있다 따라서 Kafka client는 Java NIO 를 사용한 비동기 통신 모델로 구현됨
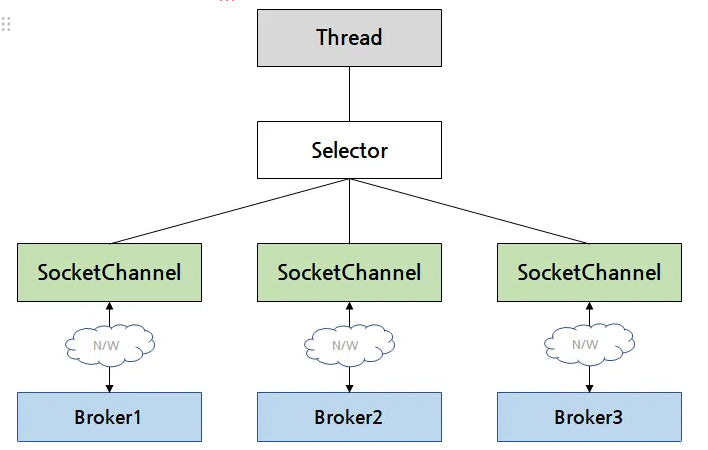
- 하나의 스레드가 Selector 라는 컴포넌트를 두고 여러 SocketChannel 을 관리할 수 있게 함
- Selector 를 이용해 관리하고 있는 SocketChannel 들 중 하나에서 읽거나, 쓰는 IO 관련 이벤트가 발생하면 바로 알 수 있음 ⇒ 멀티플렉싱
//Java NIO Selector 생성
Selector selector = Selector.open();
//브로커 노드 정보를 이용해 SocketChannel 생성
SocketChannel socketChannel = SocketChannel.open();
socketChannel.configureBlocking(false);
socketChannel.connect(new InetSocketAddress(node.host(), node.port());
//Selector에 SocketChannel 등록
//SocketChannel 에 대해 어떤 연산을 수행할 때 알림받고 싶은 지 interestSet 을 등록함
SelectionKey selectionKey = channel.register(selector, SelectionKey.OP_CONNECT | SelectionKey.OP_READ);
//interest Set에 등록된 이벤트가 발생할 때까지 timeout 때까지 대기
selector.select(timeout);
//select method 가 깨어나게 되면,
// 등록한 브로커 중 필요한 연산을 할 수 있는 SocketChannel의 SelectionKey 반환
Set<SelectionKey> selectedKeys = selector.selectedKeys();
// SelectedKeys 순회
Iterator<SelectionKey> iterator = selectedKeys.iterator();
while(iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isReadable()) {
// ... 실행 코드
}
if (key.isWritable()) {
// ... 실행 코드
}
...
}
- Interest operation 은 다음과 같음
- OP_ACCEPT: New Channel 이 accept 되고 준비되었을 때
- OP_CONNECT: Channel 연결이 완료되었을 때
- OP_READ: Channel 이 데이터가 존재하고 읽기가 준비되었을 때
- OP_WRITE: Channel 이 데이터 쓰기가 가능할 때
- kafka client 에서는 브로커와 통신을 담당하는 스레드는 NetworkClient의 poll() 메서드를 호출하게 되고, 이 메서드 내부에서는 Selector의 select() 메서드가 실행되어 브로커와의 통신이 멀티플렉싱 방식으로 처리되게 된다
//Selector.class
public void poll(long timeout) throws IOException {
if (timeout < 0L) {
throw new IllegalArgumentException("timeout should be >= 0");
} else {
boolean madeReadProgressLastCall = this.madeReadProgressLastPoll;
this.clear();
boolean dataInBuffers = !this.keysWithBufferedRead.isEmpty();
if (!this.immediatelyConnectedKeys.isEmpty() || madeReadProgressLastCall && dataInBuffers) {
timeout = 0L;
}
if (!this.memoryPool.isOutOfMemory() && this.outOfMemory) {
this.log.trace("Broker no longer low on memory - unmuting incoming sockets");
Iterator var5 = this.channels.values().iterator();
while(var5.hasNext()) {
KafkaChannel channel = (KafkaChannel)var5.next();
if (channel.isInMutableState() && !this.explicitlyMutedChannels.contains(channel)) {
channel.maybeUnmute();
}
}
this.outOfMemory = false;
}
long startSelect = this.time.nanoseconds();
//select method 실행
int numReadyKeys = this.select(timeout);
long endSelect = this.time.nanoseconds();
this.sensors.selectTime.record((double)(endSelect - startSelect), this.time.milliseconds());
if (numReadyKeys <= 0 && this.immediatelyConnectedKeys.isEmpty() && !dataInBuffers) {
this.madeReadProgressLastPoll = true;
} else {
//Selection Key 반환받게 됨
Set<SelectionKey> readyKeys = this.nioSelector.selectedKeys();
if (dataInBuffers) {
this.keysWithBufferedRead.removeAll(readyKeys);
Set<SelectionKey> toPoll = this.keysWithBufferedRead;
this.keysWithBufferedRead = new HashSet();
this.pollSelectionKeys(toPoll, false, endSelect);
}
this.pollSelectionKeys(readyKeys, false, endSelect);
readyKeys.clear();
this.pollSelectionKeys(this.immediatelyConnectedKeys, true, endSelect);
this.immediatelyConnectedKeys.clear();
}
long endIo = this.time.nanoseconds();
this.sensors.ioTime.record((double)(endIo - endSelect), this.time.milliseconds());
this.completeDelayedChannelClose(endIo);
this.maybeCloseOldestConnection(endSelect);
}
}
//SelectionKey 에 대해 다음과 method 수행
void pollSelectionKeys(Set<SelectionKey> selectionKeys, boolean isImmediatelyConnected, long currentTimeNanos) {
Iterator var5 = this.determineHandlingOrder(selectionKeys).iterator();
while(var5.hasNext()) {
SelectionKey key = (SelectionKey)var5.next();
KafkaChannel channel = this.channel(key);
long channelStartTimeNanos = this.recordTimePerConnection ? this.time.nanoseconds() : 0L;
boolean sendFailed = false;
String nodeId = channel.id();
this.sensors.maybeRegisterConnectionMetrics(nodeId);
if (this.idleExpiryManager != null) {
this.idleExpiryManager.update(nodeId, currentTimeNanos);
}
try {
//key가 READABLE 하면 channel read 시도
if (channel.ready() && (key.isReadable() || channel.hasBytesBuffered()) && !this.hasCompletedReceive(channel) && !this.explicitlyMutedChannels.contains(channel)) {
this.attemptRead(channel);
}
if (channel.hasBytesBuffered() && !this.explicitlyMutedChannels.contains(channel)) {
this.keysWithBufferedRead.add(key);
}
long nowNanos = channelStartTimeNanos != 0L ? channelStartTimeNanos : currentTimeNanos;
//key가 WRITABLE 하면 channel read 시도
try {
this.attemptWrite(key, channel, nowNanos);
} catch (Exception var20) {
Exception e = var20;
sendFailed = true;
throw e;
}
if (!key.isValid()) {
this.close(channel, Selector.CloseMode.GRACEFUL);
}
}
//..
}
}
Kafka Channel 인증, 암호화
SocketChannel을 기반으로 인증과 암호화 기능을 추가하기 위해 KafkaChannel 클래스를 구현
public class KafkaChannel {
// 브로커 ID
private final String id;
// SocketChannel과 SelectionKey를 사용한 전송 동작
private final TransportLayer transportLayer;
// Kafka 클라이언트 인증 과정
private final Authenticator authenticator;
// 브로커에서 받은 데이터
private final int maxReceiveSize;
private NetworkReceive receive;
// 브로커로 전송할 데이터
private Send send;
...
}
- Authenticator 는 kafka client 를 인증하기 위한 동작, TransportLayer 는 브로커와의 통신 암호화를 위해 설정됨
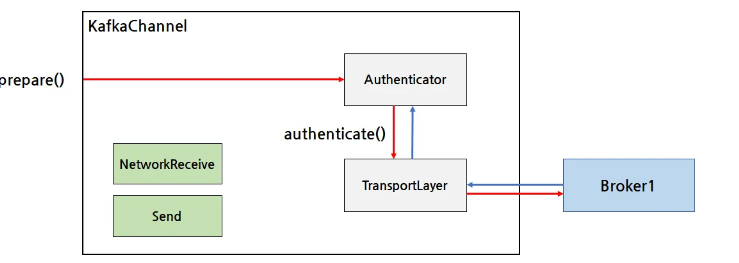
인증을 사용하면 Authenticator 가 Transfortlayer 와 인증 정보를 주고받으며 kafka client 인증을 진행함
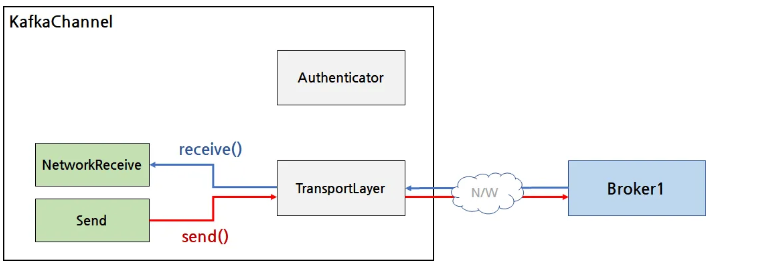
인증이 끝나면 TransportLayer 를 통해 브로커와 통신하면서 send 에 있는 데이터 (ClientRequest 를 직렬화한 byte buffer) 를 전송하거나 브로커로부터 데이터를 받아서 NetworkReceive 에 담아둠
KafkaChannel 은 브로커와의 연결이 맺어지는 과정에서 channelBuilder 에 의해 생성되고, security.protocol 설정 값에 따라 KafkaChannel 의 Authenticator 와 TransfortLayer 의 구현체가 결정됨
Metadata
kafka client 는 어떻게 특정 Topic Parition 을 담당하고 있는 broker 정보를 알고 있을까?
⇒ 메타데이터를 요청함으로써 알 수 있게 됨
Metadata에는 Kafka 클라이언트가 알아야 할 Kafka 클러스터의 메타데이터와 그 메타데이터를 갱신하기 위한 동작이 정의되어 있음
//브로커 정보를 저장하는 Node 객체
public class Node {
private final int id;
private final String idString;
private final String host;
private final int port;
private final String rack;
...
}
//파티션 정보 저장하는 객체
//복제본이 어느 브로커에서 서비스 되는지, 몇 개의 파티션인지, in-sync 복제본은 어느 브로커에 있는지
public class PartitionInfo {
private final String topic;
private final int partition;
private final Node leader;
private final Node[] replicas;
private final Node[] inSyncReplicas;
...
}
MetadataUpdater
Metadata 는 클러스터가 운영되는 도중에 바뀔 수 있음
메타데이터 갱신을 위해 MetadataUpdater 라는 클래스를 사용
현재 InFlightRequest 항목이 가장 적은 노드로 MetaData 정보를 요청하게 되는데, kakfa client 인스턴스가 최초로 생겼을 때는 메타데이터 정보를 요청할 브로커의 주소 정보를 가지고 있지 않기 때문에 bootstrap.servers 설정에 브로커 중 일부의 주소를 입력해야 함
메타데이터 업데이트 요청은 너무 빈번하게 전송되지 않아야 하므로 request.backoff.ms 설정값을 이용해 마지막 갱신 시간으로부터 그 설정값 시간이 지나지 않을 때까지 메타데이터 요청을 하지 않도록 함 또한 metada.max.age.ms 설정을 통해 설정한 시간이 지나면 메타데이터 갱신 요청을 전송함
KafkaProducer는 일정 기간 동안 사용되지 않은 토픽의 정보는 메타데이터에서 제외한다. 제외된 토픽은 앞으로 전송되는 메타데이터 갱신 요청에 포함되지 않음
출처:
https://d2.naver.com/helloworld/0974525
https://d2.naver.com/helloworld/6560422
https://d2.naver.com/helloworld/0853669
'공부 > Kafka' 카테고리의 다른 글
| 데이터 파이프라인 구축하기 (2) | 2024.12.15 |
|---|---|
| 신뢰성 있는 데이터 전달, Exactly at-once semantics (1) | 2024.11.17 |
| 카프카 컨슈머 (0) | 2024.10.20 |
| 카프카 프로듀서 (0) | 2024.10.13 |
| 카프카 기본 개념 (0) | 2024.10.06 |